This project provides Netflix OSS integrations for Spring Boot apps through autoconfiguration and binding to the Spring Environment and other Spring programming model idioms. With a few simple annotations you can quickly enable and configure the common patterns inside your application and build large distributed systems with battle-tested Netflix components. The patterns provided include Service Discovery (Eureka), Circuit Breaker (Hystrix), Intelligent Routing (Zuul) and Client Side Load Balancing (Ribbon).
Service Discovery: Eureka Clients
Service Discovery is one of the key tenets of a microservice based architecture. Trying to hand configure each client or some form of convention can be very difficult to do and can be very brittle. Eureka is the Netflix Service Discovery Server and Client. The server can be configured and deployed to be highly available, with each server replicating state about the registered services to the others.
Registering with Eureka
When a client registers with Eureka, it provides meta-data about itself such as host and port, health indicator URL, home page etc. Eureka receives heartbeat messages from each instance belonging to a service. If the heartbeat fails over a configurable timetable, the instance is normally removed from the registry.
Example eureka client:
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}(i.e. utterly normal Spring Boot app). In this example we use
@EnableEurekaClient explicitly, but with only Eureka available you
could also use @EnableDiscoveryClient. Configuration is required to
locate the Eureka server. Example:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
where "defaultZone" is a magic string fallback value that provides the service URL for any client that doesn’t express a preference (i.e. it’s a useful default).
The default application name (service ID), virtual host and non-secure
port, taken from the Environment, are ${spring.application.name},
${spring.application.name} and ${server.port} respectively.
@EnableEurekaClient makes the app into both a Eureka "instance"
(i.e. it registers itself) and a "client" (i.e. it can query the
registry to locate other services). The instance behaviour is driven
by eureka.instance.* configuration keys, but the defaults will be
fine if you ensure that your application has a
spring.application.name (this is the default for the Eureka service
ID, or VIP).
See EurekaInstanceConfigBean and EurekaClientConfigBean for more details of the configurable options.
Status Page and Health Indicator
The status page and health indicators for a Eureka instance default to
"/info" and "/health" respectively, which are the default locations of
useful endpoints in a Spring Boot Actuator application. You need to
change these, even for an Actuator application if you use a
non-default context path or servlet path
(e.g. server.servletPath=/foo) or management endpoint path
(e.g. management.contextPath=/admin). Example:
eureka:
instance:
statusPageUrlPath: ${management.contextPath}/info
healthCheckUrlPath: ${management.contextPath}/health
These links show up in the metadata that is consumers by clients, and used in some scenarios to decide whether to send requests to your application, so it’s helpful if they are accurate.
Eureka Metadata for Instances and Clients
It’s worth spending a bit of time understanding how the Eureka metadata works, so you can use it in a way that makes sense in your platform. There is standard metadata for things like hostname, IP address, port numbers, status page and health check. These are published in the service registry and used by clients to contact the services in a straightforward way. Additional metadata can be added to the instance registration in the eureka.instance.metadataMap, and this will be accessible in the remote clients, but in general will not change the behaviour of the client, unless it is made aware of the meaning of the metadata. There are a couple of special cases described below where Spring Cloud already assigns meaning to the metadata map.
Using Eureka on Cloudfoundry
Cloudfoundry has a global router so that all instances of the same app have the same hostname (it’s the same in other PaaS solutions with a similar architecture). This isn’t necessarily a barrier to using Eureka, but if you use the router (recommended, or even mandatory depending on the way your platform was set up), you need to explicitly set the hostname and port numbers (secure or non-secure) so that they use the router. You might also want to use instance metadata so you can distinguish between the instances on the client (e.g. in a custom load balancer). For example:
eureka:
instance:
hostname: ${vcap.application.uris[0]}
nonSecurePort: 80
metadataMap:
instanceId: ${vcap.application.instance_id:${spring.application.name}:${spring.application.instance_id:${server.port}}}
Depending on the way the security rules are set up in your Cloudfoundry instance, you might be able to register and use the IP address of the host VM for direct service-to-service calls. This feature is not (yet) available on Pivotal Web Services (PWS).
Using Eureka on AWS
If the application is planned to be deployed to an AWS cloud, then the Eureka instance will have to be configured to be Amazon aware and this can be done by customizing the EurekaInstanceConfigBean the following way:
@Bean
@Profile("!default")
public EurekaInstanceConfigBean eurekaInstanceConfig() {
EurekaInstanceConfigBean b = new EurekaInstanceConfigBean();
AmazonInfo info = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
b.setDataCenterInfo(info);
return b;
}Making the Eureka Instance ID Unique
By default a eureka instance is registered with an ID that is equal to its host name (i.e. only one service per host). Using Spring Cloud you can override this by providing a unique identifier in eureka.instance.metadataMap.instanceId. For example:
eureka:
instance:
metadataMap:
instanceId: ${spring.application.name}:${spring.application.instance_id:${random.value}}
With this metadata, and multiple service instances deployed on
localhost, the random value will kick in there to make the instance
unique. In Cloudfoundry the spring.application.instance_id will be
populated automatically in a Spring Boot Actuator application, so the
random value will not be needed.
Using the DiscoveryClient
Once you have an app that is @EnableEurekaClient you can use it to
discover service instances from the Eureka Server. One way to do that is to use the native
com.netflix.discovery.DiscoveryClient (as opposed to the Spring
Cloud DiscoveryClient), e.g.
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
InstanceInfo instance = discoveryClient.getNextServerFromEureka("STORES", false);
return instance.getHomePageUrl();
}
|
Tip
|
Don’t use the |
Alternatives to the native Netflix DiscoveryClient
You don’t have to use the raw Netflix DiscoveryClient and usually it
is more convenient to use it behind a wrapper of some sort. Spring
Cloud has support for Feign (a REST client
builder) and also Spring RestTemplate using
the logical Eureka service identifiers (VIPs) instead of physical
URLs. To configure Ribbon with a fixed list of physical servers you
can simply set <client>.ribbon.listOfServers to a comma-separated
list of physical addresses (or hostnames), where <client> is the ID
of the client.
You can also use the org.springframework.cloud.client.discovery.DiscoveryClient
which provides a simple API for discovery clients that is not specific
to Netflix, e.g.
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = client.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
Why is it so Slow to Register a Service?
Being an instance also involves a periodic heartbeat to the registry
(via the client’s serviceUrl) with default duration 30 seconds. A
service is not available for discovery by clients until the instance,
the server and the client all have the same metadata in their local
cache (so it could take 3 hearbeats). You can change the period using
eureka.instance.leaseRenewalIntervalInSeconds and this will speed up
the process of getting clients connected to other services. In
production it’s probably better to stick with the default because
there are some computations internally in the server that make
assumptions about the lease renewal period.
Service Discovery: Eureka Server
Example eureka server (e.g. using spring-cloud-starter-eureka-server to set up the classpath):
@SpringBootApplication
@EnableEurekaServer
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}The server has a home page with a UI, and HTTP API endpoints per the
normal Eureka functionality under /eureka/*.
Eureka background reading: see flux capacitor and google group discussion.
|
Tip
|
Due to Gradle’s dependency resolution rules and the lack of a parent bom feature, simply depending on spring-cloud-starter-eureka-server can cause failures on application startup. To remedy this the Spring dependency management plugin must be added and the Spring cloud starter parent bom must be imported like so: build.gradle
|
High Availability, Zones and Regions
The Eureka server does not have a backend store, but the service instances in the registry all have to send heartbeats to keep their registrations up to date (so this can be done in memory). Clients also have an in-memory cache of eureka registrations (so they don’t have to go to the registry for every single request to a service).
By default every Eureka server is also a Eureka client and requires (at least one) service URL to locate a peer. If you don’t provide it the service will run and work, but it will shower your logs with a lot of noise about not being able to register with the peer.
See also below for details of Ribbon support on the client side for Zones and Regions.
Standalone Mode
The combination of the two caches (client and server) and the heartbeats make a standalone Eureka server fairly resilient to failure, as long as there is some sort of monitor or elastic runtime keeping it alive (e.g. Cloud Foundry). In standalone mode, you might prefer to switch off the client side behaviour, so it doesn’t keep trying and failing to reach its peers. Example:
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
Notice that the serviceUrl is pointing to the same host as the local
instance.
Peer Awareness
Eureka can be made even more resilient and available by running
multiple instances and asking them to register with each other. In
fact, this is the default behaviour, so all you need to do to make it
work is add a valid serviceUrl to a peer, e.g.
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
client:
serviceUrl:
defaultZone: http://peer2/eureka/
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
client:
serviceUrl:
defaultZone: http://peer1/eureka/
In this example we have a YAML file that can be used to run the same
server on 2 hosts (peer1 and peer2), by running it in different
Spring profiles. You could use this configuration to test the peer
awareness on a single host (there’s not much value in doing that in
production) by manipulating /etc/hosts to resolve the host names. In
fact, the eureka.instance.hostname is not needed if you are running
on a machine that knows its own hostname (it is looked up using
java.net.InetAddress by default).
You can add multiple peers to a system, and as long as they are all connected to each other by at least one edge, they will synchronize the registrations amongst themselves. If the peers are physically separated (inside a data centre or between multiple data centres) then the system can in principle survive split-brain type failures.
Prefer IP Address
In some cases, it is preferable for Eureka to advertise the IP Adresses
of services rather than the hostname. Set eureka.instance.preferIpAddress
to true and when the application registers with eureka, it will use its
IP Address rather than its hostname.
Circuit Breaker: Hystrix Clients
Netflix has created a library called Hystrix that implements the circuit breaker pattern. In a microservice architecture it is common to have multiple layers of service calls.
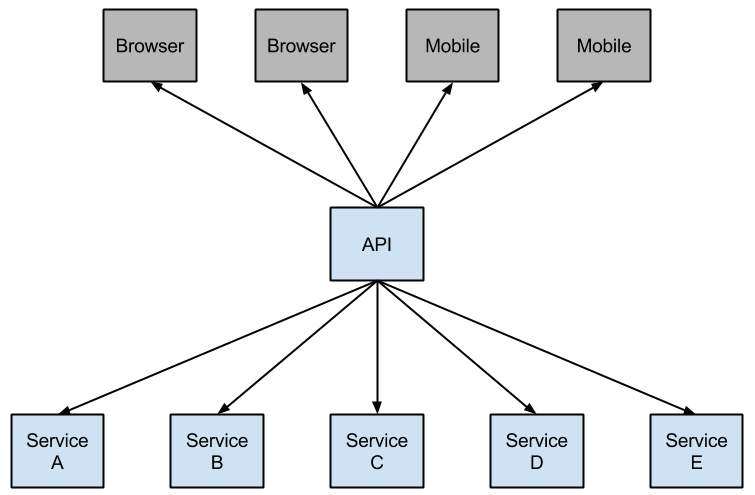
A service failure in the lower level of services can cause cascading failure all the way up to the user. When calls to a particular service reach a certain threshold (20 failures in 5 seconds is the default in Hystrix), the circuit opens and the call is not made. In cases of error and an open circuit a fallback can be provided by the developer.
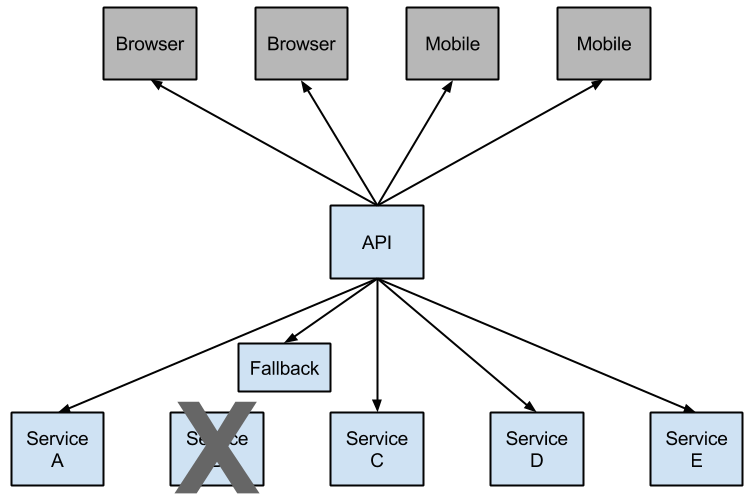
Having an open circuit stops cascading failures and allows overwhelmed or failing services time to heal. The fallback can be another Hystrix protected call, static data or a sane empty value. Fallbacks may be chained so the first fallback makes some other business call which in turn falls back to static data.
Example boot app:
@SpringBootApplication
@EnableCircuitBreaker
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
@Component
public class StoreIntegration {
@HystrixCommand(fallbackMethod = "defaultStores")
public Object getStores(Map<String, Object> parameters) {
//do stuff that might fail
}
public Object defaultStores(Map<String, Object> parameters) {
return /* something useful */;
}
}
The @HystrixCommand is provided by a Netflix contrib library called
"javanica".
Spring Cloud automatically wraps Spring beans with that
annotation in a proxy that is connected to the Hystrix circuit
breaker. The circuit breaker calculates when to open and close the
circuit, and what to do in case of a failure.
To configure the @HystrixCommand you can use the commandProperties
attribute with a list of @HystrixProperty annotations. See
here
for more details. See the Hystrix wiki
for details on the properties available.
Propagating the Security Context or using Spring Scopes
If you want some thread local context to propagate into a @HystrixCommand the default declaration will not work because it executes the command in a thread pool (in case of timeouts). You can switch Hystrix to use the same thread as the caller using some configuration, or directly in the annotation, by asking it to use a different "Isolation Strategy". For example:
@HystrixCommand(fallbackMethod = "stubMyService",
commandProperties = {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")
}
)
...The same thing applies if you are using @SessionScope or @RequestScope. You will know when you need to do this because of a runtime exception that says it can’t find the scoped context.
In particular you might be interested
Health Indicator
The state of the connected circuit breakers are also exposed in the
/health endpoint of the calling application.
{
"hystrix": {
"openCircuitBreakers": [
"StoreIntegration::getStoresByLocationLink"
],
"status": "CIRCUIT_OPEN"
},
"status": "UP"
}Hystrix Metrics Stream
To enable the Hystrix metrics stream include a dependency on spring-boot-starter-actuator. This will expose the /hystrix.stream as a management endpoint.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Circuit Breaker: Hystrix Dashboard
One of the main benefits of Hystrix is the set of metrics it gathers about each HystrixCommand. The Hystrix Dashboard displays the health of each circuit breaker in an efficient manner.
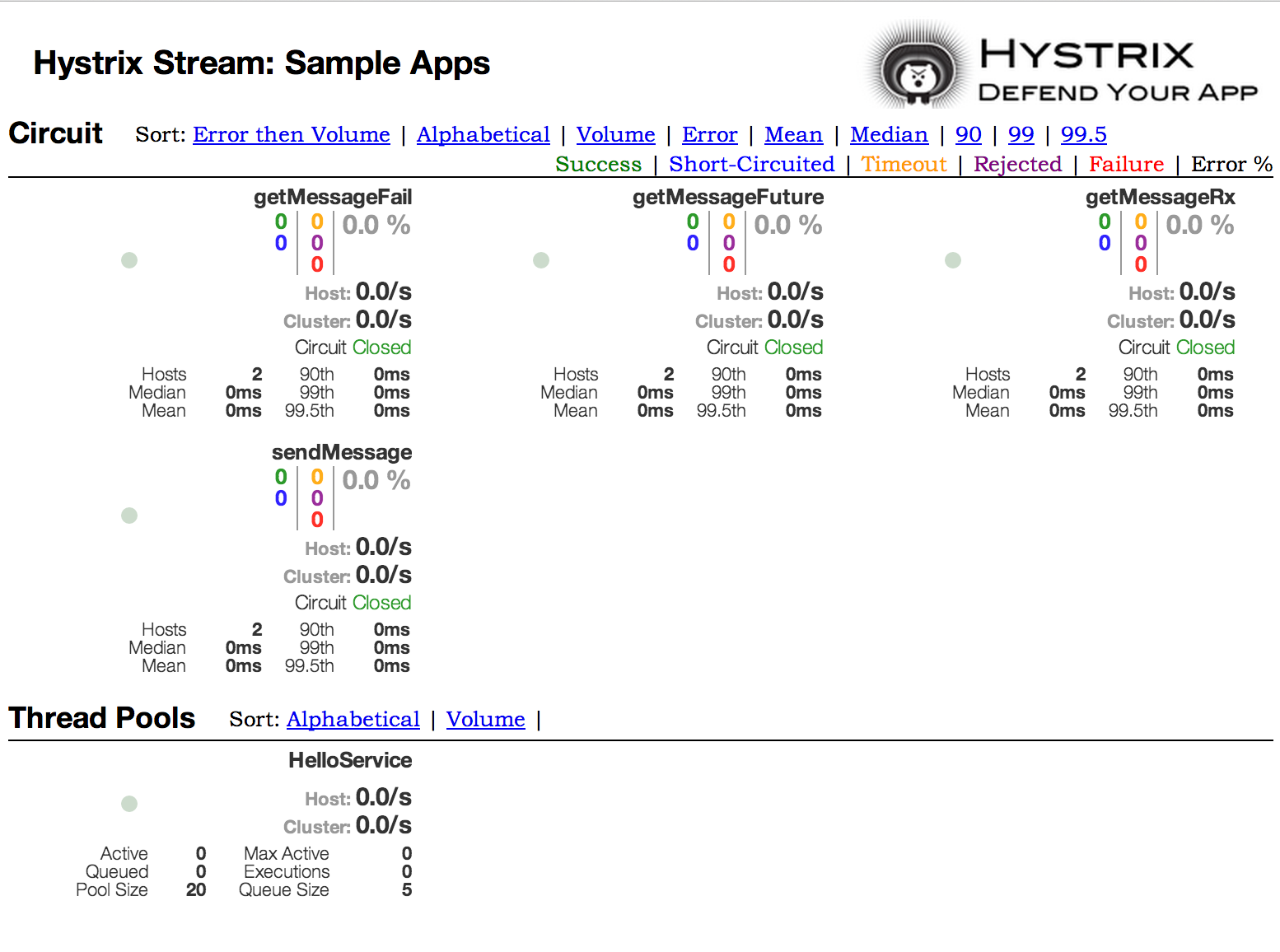
To run the Hystrix Dashboard annotate your Spring Boot main class with @EnableHystrixDashboard. You then visit /hystrix and point the dashboard to an individual instances /hystrix.stream endpoint in a Hystrix client application.
Turbine
Looking at an individual instances Hystrix data is not very useful in terms of the overall health of the system. Turbine is an application that aggregates all of the relevant /hystrix.stream endpoints into a combined /turbine.stream for use in the Hystrix Dashboard. Individual instances are located via Eureka. Running Turbine is as simple as annotating your main class with the @EnableTurbine annotation (e.g. using spring-cloud-starter-turbine to set up the classpath). All of the documented configuration properties from the Turbine 1 wiki apply. The only difference is that the turbine.instanceUrlSuffix does not need the port prepended as this is handled automatically unless turbine.instanceInsertPort=false.
The configuration key turbine.appConfig is a list of eureka serviceIds that turbine will use to lookup instances. The turbine stream is then used in the Hystrix dashboard using a url that looks like: https://my.turbine.sever:8080/turbine.stream?cluster=<CLUSTERNAME>; (the cluster parameter can be omitted if the name is "default"). The cluster parameter must match an entry in turbine.aggregator.clusterConfig. Values returned from eureka are uppercase, thus we expect this example to work if there is an app registered with Eureka called "customers":
turbine:
aggregator:
clusterConfig: CUSTOMERS
appConfig: customers
The clusterName can be customized by a SPEL expression in turbine.clusterNameExpression with root an instance of InstanceInfo. The default value is appName, which means that the Eureka serviceId ends up as the cluster key (i.e. the InstanceInfo for customers has an appName of "CUSTOMERS"). A different example would be turbine.clusterNameExpression=aSGName, which would get the cluster name from the AWS ASG name. Another example:
turbine:
aggregator:
clusterConfig: SYSTEM,USER
appConfig: customers,stores,ui,admin
clusterNameExpression: metadata['cluster']
In this case, the cluster name from 4 services is pulled from their metadata map, and is expected to have values that include "SYSTEM" and "USER".
To use the "default" cluster for all apps you need a string literal expression (with single quotes):
turbine: appConfig: customers,stores clusterNameExpression: 'default'
Spring Cloud provides a spring-cloud-starter-turbine that has all the dependencies you need to get a Turbine server running. Just create a Spring Boot application and annotate it with @EnableTurbine.
Turbine AMQP
In some environments (e.g. in a PaaS setting), the classic Turbine model of pulling metrics from all the distributed Hystrix commands doesn’t work. In that case you might want to have your Hystrix commands push metrics to Turbine, and Spring Cloud enables that with AMQP messaging. All you need to do on the client is add a dependency to spring-cloud-netflix-hystrix-amqp and make sure there is a Rabbit broker available (see Spring Boot documentation for details on how to configure the client credentials, but it should work out of the box for a local broker or in Cloud Foundry).
On the server side Just create a Spring Boot application and annotate it with @EnableTurbineAmqp and by default it will come up on port 8989 (point your Hystrix dashboard to that port, any path). You can customize the port using either server.port or turbine.amqp.port. If you have spring-boot-starter-web and spring-boot-starter-actuator on the classpath as well, then you can open up the Actuator endpoints on a separate port (with Tomcat by default) by providing a management.port which is different.
You can then point the Hystrix Dashboard to the Turbine AMQP Server instead of individual Hystrix streams. If Turbine AMQP is running on port 8989 on myhost, then put http://myhost:8989 in the stream input field in the Hystrix Dashboard. Circuits will be prefixed by their respective serviceId, followed by a dot, then the circuit name.
Spring Cloud provides a spring-cloud-starter-turbine-amqp that has all the dependencies you need to get a Turbine AMQP server running. You need Java 8 to run the app because it is Netty-based.
Customizing the AMQP ConnectionFactory
If you are using AMQP there needs to be a ConnectionFactory (from
Spring Rabbit) in the application context. If there is a single
ConnectionFactory it will be used, or if there is a one qualified as
@HystrixConnectionFactory (on the client) and
@TurbineConnectionFactory (on the server) it will be preferred over
others, otherwise the @Primary one will be used. If there are
multiple unqualified connection factories there will be an error.
Note that Spring Boot (as of 1.2.2) creates a ConnectionFactory that
is not @Primary, so if you want to use one connection factory for
the bus and another for business messages, you need to create both,
and annotate them @*ConnectionFactory and @Primary respectively.
Client Side Load Balancer: Ribbon
Ribbon is a client side load balancer which gives you a lot of control
over the behaviour of HTTP and TCP clients. Feign already uses Ribbon,
so if you are using @FeignClient then this section also applies.
A central concept in Ribbon is that of the named client. Each load
balancer is part of an ensemble of components that work together to
contact a remote server on demand, and the ensemble has a name that
you give it as an application developer (e.g. using the @FeignClient
annotation). Spring Cloud creates a new ensemble as an
ApplicationContext on demand for each named client using
RibbonClientConfiguration. This contains (amongst other things) an
ILoadBalancer, a RestClient, and a ServerListFilter.
Customizing the Ribbon Client
You can configure some bits of a Ribbon client using external
properties in <client>.ribbon.*, which is no different than using
the Netflix APIs natively, except that you can use Spring Boot
configuration files. The native options can
be inspected as static fields in CommonClientConfigKey (part of
ribbon-core).
Spring Cloud also lets you take full control of the client by
declaring additional configuration (on top of the
RibbonClientConfiguration) using @RibbonClient. Example:
@Configuration
@RibbonClient(name = "foo", configuration = FooConfiguration.class)
public class TestConfiguration {
}In this case the client is composed from the components already in
RibbonClientConfiguration together with any in FooConfiguration
(where the latter generally will override the former).
|
Warning
|
The FooConfiguration has to be @Configuration but take
care that it is not in a @ComponentScan for the main application
context, otherwise it will be shared by all the @RibbonClients. If
you use @ComponentScan (or @SpringBootApplication) you need to
take steps to avoid it being included (for instance put it in a
separate, non-overlapping package, or specify the packages to scan
explicitly in the @ComponentScan).
|
Spring Cloud Netflix provides the following beans by default for ribbon
(BeanType beanName: ClassName):
-
IClientConfigribbonClientConfig:DefaultClientConfigImpl -
IRuleribbonRule:ZoneAvoidanceRule -
IPingribbonPing:NoOpPing -
ServerList<Server> ribbonServerList: `ConfigurationBasedServerList -
ServerListFilter<Server>ribbonServerListFilter:ZonePreferenceServerListFilter -
ILoadBalancerribbonLoadBalancer:ZoneAwareLoadBalancer
Creating a bean of one of those type and placing it in a @RibbonClient
configuration (such as FooConfiguration above) allows you to override each
one of the beans described. Example:
@Configuration
public class FooConfiguration {
@Bean
public IPing ribbonPing(IClientConfig config) {
return new PingUrl();
}
}This replaces the NoOpPing with PingUrl.
Using Ribbon with Eureka
When Eureka is used in conjunction with Ribbon the ribbonServerList
is overridden with an extension of DiscoveryEnabledNIWSServerList
which populates the list of servers from Eureka. It also replaces the
IPing interface with NIWSDiscoveryPing which delegates to Eureka
to determine if a server is up. The ServerList that is installed by
default is a DomainExtractingServerList and the purpose of this is
to make physical metadata available to the load balancer without using
AWS AMI metadata (which is what Netflix relies on). By default the
server list will be constructed with "zone" information as provided in
the instance metadata (so on the client set
eureka.instance.metadataMap.zone), and if that is missing it can use
the domain name from the server hostname as a proxy for zone (if the
flag approximateZoneFromDomain is set). Once the zone information is
available it can be used in a ServerListFilter (by default it will
be used to locate a server in the same zone as the client because the
default is a ZonePreferenceServerListFilter).
Example: How to Use Ribbon Without Eureka
Eureka is a convenient way to abstract the discovery of remote servers
so you don’t have to hard code their URLs in clients, but if you
prefer not to use it, Ribbon and Feign are still quite
amenable. Suppose you have declared a @RibbonClient for "stores",
and Eureka is not in use (and not even on the classpath). The Ribbon
client defaults to a configured server list, and you can supply the
configuration like this
stores:
ribbon:
listOfServers: example.com,google.com
Example: Disable Eureka use in Ribbon
Setting the property ribbon.eureka.enabled = false will explicitly
disable the use of Eureka in Ribbon.
ribbon: eureka: enabled: false
Using the Ribbon API Directly
You can also use the LoadBalancerClient directly. Example:
public class MyClass {
@Autowired
private LoadBalancerClient loadBalancer;
public void doStuff() {
ServiceInstance instance = loadBalancer.choose("stores");
URI storesUri = URI.create(String.format("http://%s:%s", instance.getHost(), instance.getPort()));
// ... do something with the URI
}
}Declarative REST Client: Feign
Feign is a declarative web service client. It makes writing web service clients easier. To use Feign create an interface and annotate it. It has pluggable annotation support including Feign annotations and JAX-RS annotations. Feign also supports pluggable encoders and decoders. Spring Cloud adds support for Spring MVC annotations and for using the same HttpMessageConverters used by default in Spring Web. Spring Cloud integrates Ribbon and Eureka to provide a load balanced http client when using Feign.
Example spring boot app
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@EnableFeignClients
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}@FeignClient("stores")
public interface StoreClient {
@RequestMapping(method = RequestMethod.GET, value = "/stores")
List<Store> getStores();
@RequestMapping(method = RequestMethod.POST, value = "/stores/{storeId}", consumes = "application/json")
Store update(@PathParameter("storeId") Long storeId, Store store);
}In the @FeignClient annotation the String value ("stores" above) is
an arbitrary client name, which is used to create a Ribbon load
balancer (see below for details of Ribbon
support). You can also specify a URL using the url attribute
(absolute value or just a hostname).
The Ribbon client above will want to discover the physical addresses for the "stores" service. If your application is a Eureka client then it will resolve the service in the Eureka service registry. If you don’t want to use Eureka, you can simply configure a list of servers in your external configuration (see above for example).
External Configuration: Archaius
Archaius is the Netflix client side configuration library. It is the library used by all of the Netflix OSS components for configuration. Archaius is an extension of the Apache Commons Configuration project. It allows updates to configuration by either polling a source for changes or for a source to push changes to the client. Archaius uses Dynamic<Type>Property classes as handles to properties.
class ArchaiusTest {
DynamicStringProperty myprop = DynamicPropertyFactory
.getInstance()
.getStringProperty("my.prop");
void doSomething() {
OtherClass.someMethod(myprop.get());
}
}Archaius has its own set of configuration files and loading priorities. Spring applications should generally not use Archaius directly., but the need to configure the Netflix tools natively remains. Spring Cloud has a Spring Environment Bridge so Archaius can read properties from the Spring Environment. This allows Spring Boot projects to use the normal configuration toolchain, while allowing them to configure the Netflix tools, for the most part, as documented.
Router and Filter: Zuul
Routing in an integral part of a microservice architecture. For example, / may be mapped to your web application, /api/users is mapped to the user service and /api/shop is mapped to the shop service. Zuul is a JVM based router and server side load balancer by Netflix.
Netflix uses Zuul for the following:
-
Authentication
-
Insights
-
Stress Testing
-
Canary Testing
-
Dynamic Routing
-
Service Migration
-
Load Shedding
-
Security
-
Static Response handling
-
Active/Active traffic management
Zuul’s rule engine allows rules and filters to be written in essentially any JVM language, with built in support for Java and Groovy.
Embedded Zuul Reverse Proxy
Spring Cloud has created an embedded Zuul proxy to ease the development of a very common use case where a UI application wants to proxy calls to one or more back end services. This feature is useful for a user interface to proxy to the backend services it requires, avoiding the need to manage CORS and authentication concerns independently for all the backends.
To enable it, annotate a Spring Boot main class with
@EnableZuulProxy, and this forwards local calls to the appropriate
service. By convention, a service with the Eureka ID "users", will
receive requests from the proxy located at /users (with the prefix
stripped). The proxy uses Ribbon to locate an instance to forward to
via Eureka, and all requests are executed in a hystrix command, so
failures will show up in Hystrix metrics, and once the circuit is open
the proxy will not try to contact the service.
To skip having a service automatically added, set
zuul.ignored-services to a list of service id patterns. If a service
matches a pattern that is ignored, but also included in the explicitly
configured routes map, then it will be unignored. Example:
zuul:
ignoredServices: *
routes:
users: /myusers/**In this example, all services are ignored except "users".
To augment or change the proxy routes, you can add external configuration like the following:
zuul:
routes:
users: /myusers/**This means that http calls to "/myusers" get forwarded to the "users" service (for example "/myusers/101" is forwarded to "/101").
To get more fine-grained control over a route you can specify the path and the serviceId independently:
zuul:
routes:
users:
path: /myusers/**
serviceId: users_serviceThis means that http calls to "/myusers" get forwarded to the "users_service" service. The route has to have a "path" which can be specified as an ant-style pattern, so "/myusers/*" only matches one level, but "/myusers/**" matches hierarchically.
The location of the backend can be specified as either a "serviceId" (for a Eureka service) or a "url" (for a physical location), e.g.
zuul:
routes:
users:
path: /myusers/**
url: https://example.com/users_serviceThese simple url-routes doesn’t get executed as HystrixCommand nor can you loadbalance multiple url with Ribbon. To achieve this specify a service-route and configure a Ribbon client for the serviceId (this currently requires disabling Eureka support in Ribbon: see above for more information), e.g.
zuul:
routes:
users:
path: /myusers/**
serviceId: users
ribbon:
eureka:
enabled: false
users:
ribbon:
listOfServers: example.com,google.comTo add a prefix to all mappings, set zuul.prefix to a value, such as
/api. The proxy prefix is stripped from the request before the
request is forwarded by default (switch this behaviour off with
zuul.stripPrefix=false). You can also switch off the stripping of
the service-specific prefix from individual routes, e.g.
zuul:
routes:
users:
path: /myusers/**
stripPrefix: falseIn this example requests to "/myusers/101" will be forwarded to "/myusers/101" on the "users" service.
The zuul.routes entries actually bind to an object of type ProxyRouteLocator. If you
look at the properties of that object you will see that it also has a "retryable" flag.
Set that flag to "true" to have the Ribbon client automatically retry failed requests
(and if you need to you can modify the parameters of the retry operations using
the Ribbon client configuration).
The X-Forwarded-Host header added to the forwarded requests by
default. To turn it off set zuul.addProxyHeaders = false. The
prefix path is stripped by default, and the request to the backend
picks up a header "X-Forwarded-Prefix" ("/myusers" in the examples
above).
An application with the @EnableZuulProxy could act as a standalone
server if you set a default route ("/"), for example zuul.route.home:
/ would route all traffic (i.e. "/**") to the "home" service.
Uploading Files through Zuul
If you @EnableZuulProxy you can use the proxy paths to
upload files and it should just work as long as the files
are small. For large files there is an alternative path
which bypasses the Spring DispatcherServlet (to
avoid multipart processing) in "/zuul/". I.e. if
zuul.routes.customers=/customers/* then you can
POST large files to "/zuul/customers/*". The servlet
path is externalized via zuul.servletPath. Extremely
large files will also require elevated timeout settings
if the proxy route takes you through a Ribbon load
balancer, e.g.
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000Note that for streaming to work with large files, you need to use chunked encoding in the request (which some browsers do not do by default). E.g. on the command line:
$ curl -v -H "Transfer-Encoding: chunked" \
-F "[email protected]" localhost:9999/zuul/simple/file
Plain Embedded Zuul
You can also run a Zuul server without the proxying, or switch on parts of the proxying platform selectively, if you
use @EnableZuulServer (instead of @EnableZuulProxy). Any beans that you add to the application of type ZuulFilter
will be installed automatically, as they are with @EnableZuulProxy, but without any of the proxy filters being added
automatically.
In this case the routes into the Zuul server are still specified by configuring "zuul.routes.*", but there is no service discovery and no proxying, so the "serviceId" and "url" settings are ignored. For example:
zuul:
routes:
api: /api/**maps all paths in "/api/**" to the Zuul filter chain.
Disable Zuul Filters
Zuul for Spring Cloud comes with a number of ZuulFilter beans enabled by default
in both proxy and server mode. See the zuul filters package for the
possible filters that are enabled. If you want to disable one, simply set
zuul.<SimpleClassName>.<filterType>.disable=true. By convention, the package after
filters is the Zuul filter type. For example to disable
org.springframework.cloud.netflix.zuul.filters.post.SendResponseFilter set
zuul.SendResponseFilter.post.disable=true.
Polyglot support with Sidecar
Do you have non-jvm languages you want to take advantage of Eureka, Ribbon and Config Server? The Spring Cloud Netflix Sidecar was inspired by Netflix Prana. It includes a simple http api to get all of the instances (ie host and port) for a given service. You can also proxy service calls through an embedded Zuul proxy which gets its route entries from Eureka. The Spring Cloud Config Server can be accessed directly via host lookup or through the Zuul Proxy. The non-jvm app should implement a health check so the Sidecar can report to eureka if the app is up or down.
To enable the Sidecar, create a Spring Boot application with @EnableSidecar.
This annotation includes @EnableCircuitBreaker, @EnableDiscoveryClient,
and @EnableZuulProxy. Run the resulting application on the same host as the
non-jvm application.
To configure the side car add sidecar.port and sidecar.health-uri to application.yml.
The sidecar.port property is the port the non-jvm app is listening on. This
is so the Sidecar can properly register the app with Eureka. The sidecar.health-uri
is a uri accessible on the non-jvm app that mimicks a Spring Boot health
indicator. It should return a json document like the following:
{
"status":"UP"
}Here is an example application.yml for a Sidecar application:
server:
port: 5678
spring:
application:
name: sidecar
sidecar:
port: 8000
health-uri: http://localhost:8000/health.jsonThe api for the DiscoveryClient.getInstances() method is /hosts/{serviceId}.
Here is an example response for /hosts/customers that returns two instances on
different hosts. This api is accessible to the non-jvm app (if the sidecar is
on port 5678) at http://localhost:5678/hosts/{serviceId}.
[
{
"host": "myhost",
"port": 9000,
"uri": "http://myhost:9000",
"serviceId": "CUSTOMERS",
"secure": false
},
{
"host": "myhost2",
"port": 9000,
"uri": "http://myhost2:9000",
"serviceId": "CUSTOMERS",
"secure": false
}
]The Zuul proxy automatically adds routes for each service known in eureka to
/<serviceId>, so the customers service is available at /customers. The
Non-jvm app can access the customer service via http://localhost:5678/customers
(assuming the sidecar is listening on port 5678).
If the Config Server is registered with Eureka, non-jvm application can access
it via the Zuul proxy. If the serviceId of the ConfigServer is configserver
and the Sidecar is on port 5678, then it can be accessed at
http://localhost:5678/configserver
Non-jvm app can take advantage of the Config Server’s ability to return YAML documents. For example, a call to https://sidecar.local.spring.io:5678/configserver/default-master.yml might result in a YAML document like the following
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
password: password
info:
description: Spring Cloud Samples
url: https://github.com/spring-cloud-samples