Spring Cloud Sleuth implements a distributed tracing solution for Spring Cloud.
Spring Cloud Sleuth borrows Dapper’s terminology.
Span: The basic unit of work. For example, sending an RPC is a new span, as is sending a response to an RPC. Spans are identified by a unique 64-bit ID for the span and another 64-bit ID for the trace the span is a part of. Spans also have other data, such as descriptions, timestamped events, key-value annotations (tags), the ID of the span that caused them, and process IDs (normally IP addresses).
Spans can be started and stopped, and they keep track of their timing information. Once you create a span, you must stop it at some point in the future.
![[Tip]](images/tip.png) | Tip |
|---|---|
The initial span that starts a trace is called a |
Trace: A set of spans forming a tree-like structure.
For example, if you run a distributed big-data store, a trace might be formed by a PUT request.
Annotation: Used to record the existence of an event in time. With Brave instrumentation, we no longer need to set special events for Zipkin to understand who the client and server are, where the request started, and where it ended. For learning purposes, however, we mark these events to highlight what kind of an action took place.
- cs: Client Sent. The client has made a request. This annotation indicates the start of the span.
- sr: Server Received: The server side got the request and started processing it.
Subtracting the
cstimestamp from this timestamp reveals the network latency. - ss: Server Sent. Annotated upon completion of request processing (when the response got sent back to the client).
Subtracting the
srtimestamp from this timestamp reveals the time needed by the server side to process the request. - cr: Client Received. Signifies the end of the span.
The client has successfully received the response from the server side.
Subtracting the
cstimestamp from this timestamp reveals the whole time needed by the client to receive the response from the server.
The following image shows how Span and Trace look in a system, together with the Zipkin annotations:
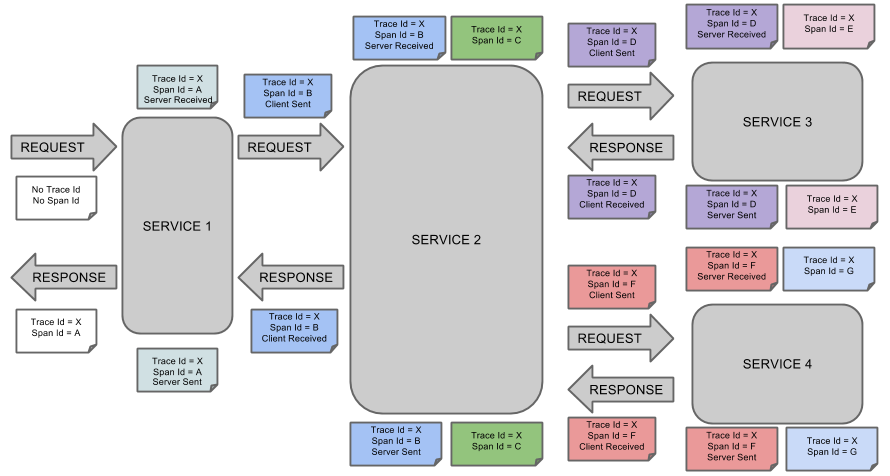
Each color of a note signifies a span (there are seven spans - from A to G). Consider the following note:
Trace Id = X Span Id = D Client Sent
This note indicates that the current span has Trace Id set to X and Span Id set to D.
Also, the Client Sent event took place.
The following image shows how parent-child relationships of spans look:
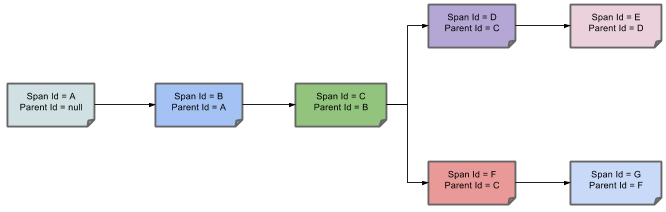
The following sections refer to the example shown in the preceding image.
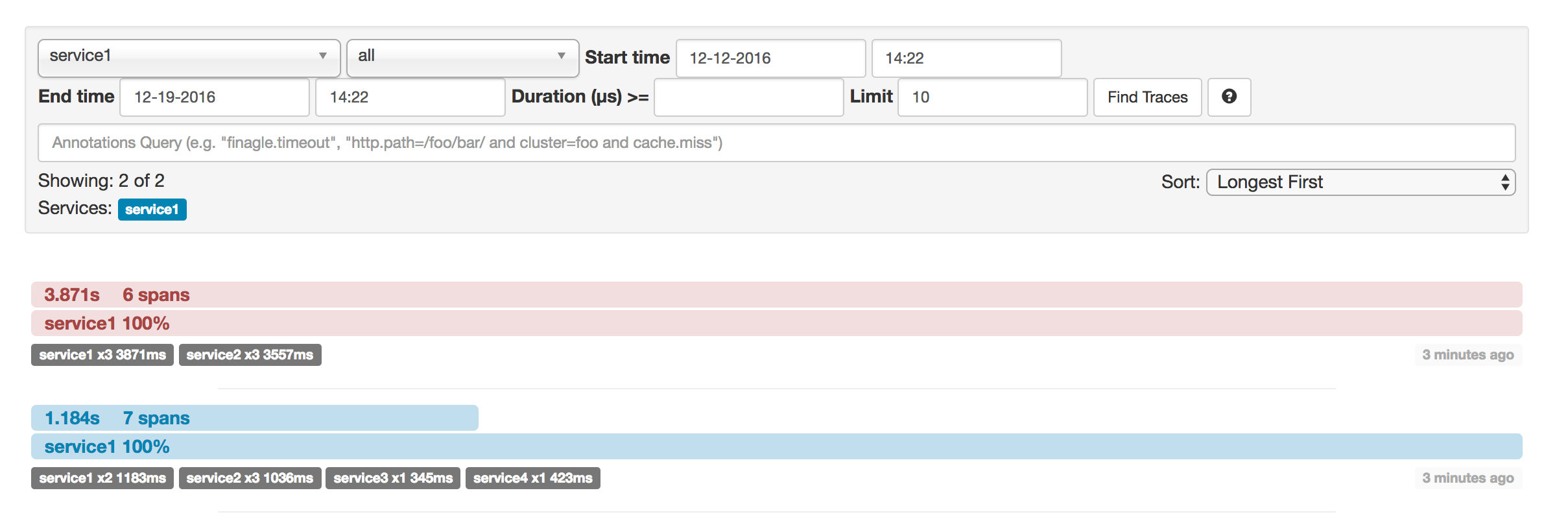
This example has seven spans. If you go to traces in Zipkin, you can see this number in the second trace, as shown in the following image:
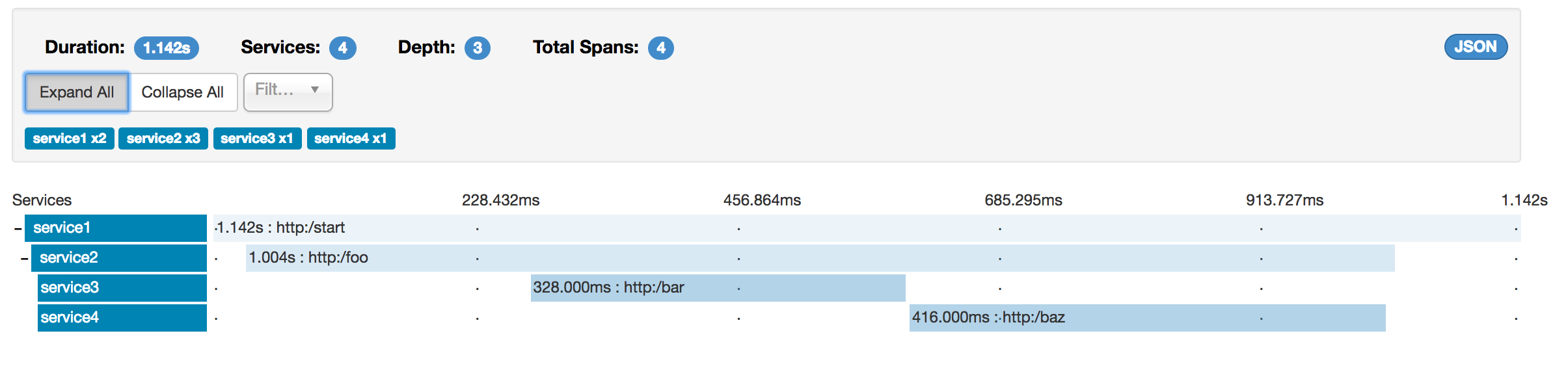
However, if you pick a particular trace, you can see four spans, as shown in the following image:
![[Note]](images/note.png) | Note |
|---|---|
When you pick a particular trace, you see merged spans. That means that, if there were two spans sent to Zipkin with Server Received and Server Sent or Client Received and Client Sent annotations, they are presented as a single span. |
Why is there a difference between the seven and four spans in this case?
- Two spans come from the
http:/startspan. It has the Server Received (sr) and Server Sent (ss) annotations. - Two spans come from the RPC call from
service1toservice2to thehttp:/fooendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice1side. Server Received (sr) and Server Sent (ss) events took place on theservice2side. These two spans form one logical span related to an RPC call. - Two spans come from the RPC call from
service2toservice3to thehttp:/barendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice2side. The Server Received (sr) and Server Sent (ss) events took place on theservice3side. These two spans form one logical span related to an RPC call. - Two spans come from the RPC call from
service2toservice4to thehttp:/bazendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice2side. Server Received (sr) and Server Sent (ss) events took place on theservice4side. These two spans form one logical span related to an RPC call.
So, if we count the physical spans, we have one from http:/start, two from service1 calling service2, two from service2
calling service3, and two from service2 calling service4. In sum, we have a total of seven spans.
Logically, we see the information of four total Spans because we have one span related to the incoming request
to service1 and three spans related to RPC calls.
Zipkin lets you visualize errors in your trace. When an exception was thrown and was not caught, we set proper tags on the span, which Zipkin can then properly colorize. You could see in the list of traces one trace that is red. That appears because an exception was thrown.
If you click that trace, you see a similar picture, as follows:
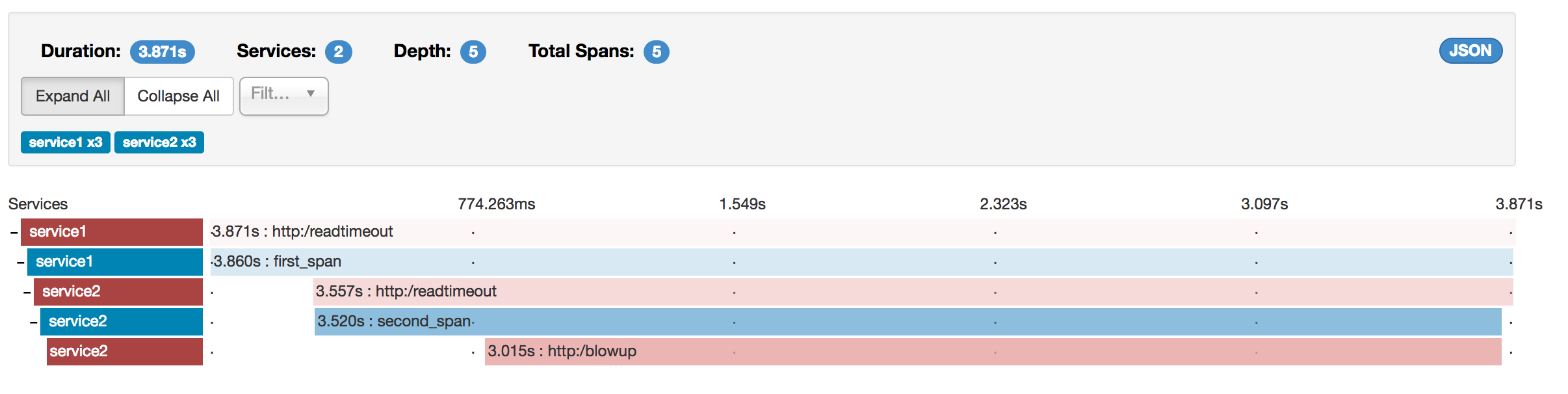
If you then click on one of the spans, you see the following
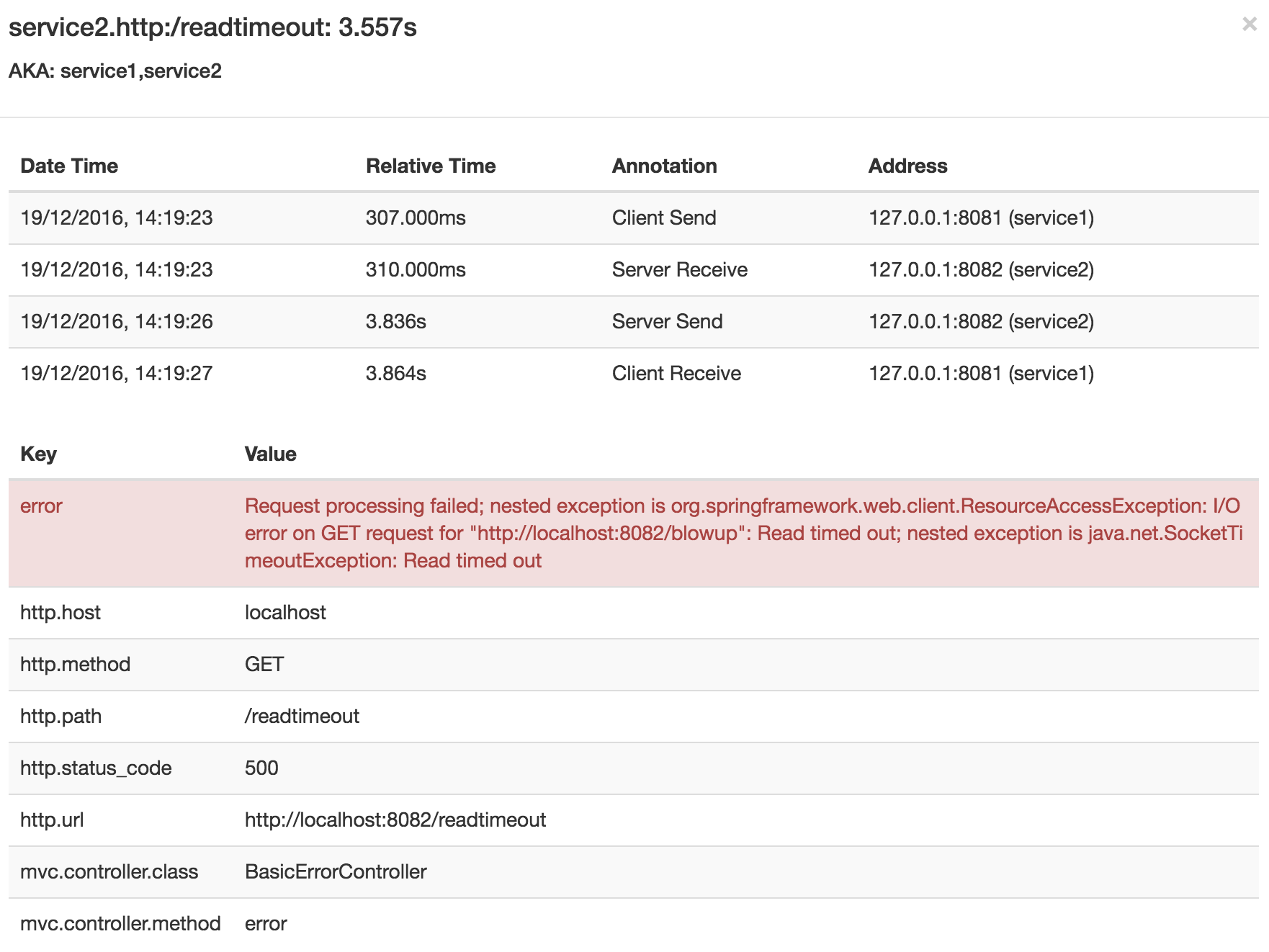
The span shows the reason for the error and the whole stack trace related to it.
Starting with version 2.0.0, Spring Cloud Sleuth uses Brave as the tracing library.
Consequently, Sleuth no longer takes care of storing the context but delegates that work to Brave.
Due to the fact that Sleuth had different naming and tagging conventions than Brave, we decided to follow Brave’s conventions from now on.
However, if you want to use the legacy Sleuth approaches, you can set the spring.sleuth.http.legacy.enabled property to true.

The dependency graph in Zipkin should resemble the following image:

When using grep to read the logs of those four applications by scanning for a trace ID equal to (for example) 2485ec27856c56f4, you get output resembling the following:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2 service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4 service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3 service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3] service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4 service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4] service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
If you use a log aggregating tool (such as Kibana, Splunk, and others), you can order the events that took place. An example from Kibana would resemble the following image:
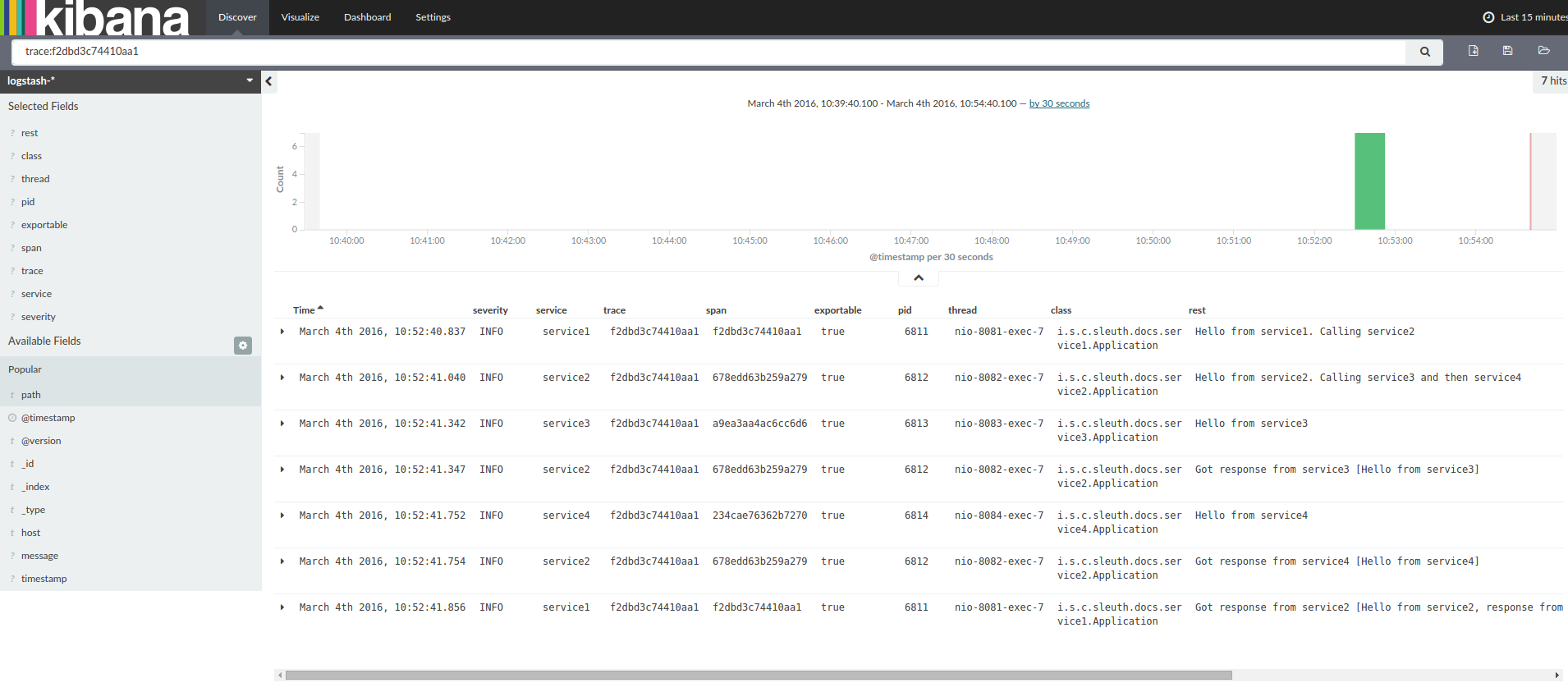
If you want to use Logstash, the following listing shows the Grok pattern for Logstash:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
} | Note |
|---|---|
If you want to use Grok together with the logs from Cloud Foundry, you have to use the following pattern: |
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}Often, you do not want to store your logs in a text file but in a JSON file that Logstash can immediately pick.
To do so, you have to do the following (for readability, we pass the dependencies in the groupId:artifactId:version notation).
Dependencies Setup
- Ensure that Logback is on the classpath (
ch.qos.logback:logback-core). - Add Logstash Logback encode. For example, to use version
4.6, addnet.logstash.logback:logstash-logback-encoder:4.6.
Logback Setup
Consider the following example of a Logback configuration file (named logback-spring.xml).
<?xml version="1.0" encoding="UTF-8"?> <configuration> <include resource="org/springframework/boot/logging/logback/defaults.xml"/> <springProperty scope="context" name="springAppName" source="spring.application.name"/> <!-- Example for logging into the build folder of your project --> <property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/> <!-- You can override this to have a custom pattern --> <property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/> <!-- Appender to log to console --> <appender name="console" class="ch.qos.logback.core.ConsoleAppender"> <filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <!-- Minimum logging level to be presented in the console logs--> <level>DEBUG</level> </filter> <encoder> <pattern>${CONSOLE_LOG_PATTERN}</pattern> <charset>utf8</charset> </encoder> </appender> <!-- Appender to log to file --> <appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_FILE}</file> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern> <maxHistory>7</maxHistory> </rollingPolicy> <encoder> <pattern>${CONSOLE_LOG_PATTERN}</pattern> <charset>utf8</charset> </encoder> </appender> <!-- Appender to log to file in a JSON format --> <appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_FILE}.json</file> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern> <maxHistory>7</maxHistory> </rollingPolicy> <encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"> <providers> <timestamp> <timeZone>UTC</timeZone> </timestamp> <pattern> <pattern> { "severity": "%level", "service": "${springAppName:-}", "trace": "%X{X-B3-TraceId:-}", "span": "%X{X-B3-SpanId:-}", "parent": "%X{X-B3-ParentSpanId:-}", "exportable": "%X{X-Span-Export:-}", "pid": "${PID:-}", "thread": "%thread", "class": "%logger{40}", "rest": "%message" } </pattern> </pattern> </providers> </encoder> </appender> <root level="INFO"> <appender-ref ref="console"/> <!-- uncomment this to have also JSON logs --> <!--<appender-ref ref="logstash"/>--> <!--<appender-ref ref="flatfile"/>--> </root> </configuration>
That Logback configuration file:
- Logs information from the application in a JSON format to a
build/${spring.application.name}.jsonfile. - Has commented out two additional appenders: console and standard log file.
- Has the same logging pattern as the one presented in the previous section.
| Note |
|---|---|
If you use a custom |
The span context is the state that must get propagated to any child spans across process boundaries. Part of the Span Context is the Baggage. The trace and span IDs are a required part of the span context. Baggage is an optional part.
Baggage is a set of key:value pairs stored in the span context.
Baggage travels together with the trace and is attached to every span.
Spring Cloud Sleuth understands that a header is baggage-related if the HTTP header is prefixed with baggage- and, for messaging, it starts with baggage_.
![[Important]](images/important.png) | Important |
|---|---|
There is currently no limitation of the count or size of baggage items. However, keep in mind that too many can decrease system throughput or increase RPC latency. In extreme cases, too much baggage can crash the application, due to exceeding transport-level message or header capacity. |
The following example shows setting baggage on a span:
Span initialSpan = this.tracer.nextSpan().name("span").start(); try (Tracer.SpanInScope ws = this.tracer.withSpanInScope(initialSpan)) { ExtraFieldPropagation.set("foo", "bar"); ExtraFieldPropagation.set("UPPER_CASE", "someValue"); }
Baggage travels with the trace (every child span contains the baggage of its parent). Zipkin has no knowledge of baggage and does not receive that information.
| Important |
|---|---|
Starting from Sleuth 2.0.0 you have to pass the baggage key names explicitly in your project configuration. Read more about that setup here |
Tags are attached to a specific span. In other words, they are presented only for that particular span. However, you can search by tag to find the trace, assuming a span having the searched tag value exists.
If you want to be able to lookup a span based on baggage, you should add a corresponding entry as a tag in the root span.
| Important |
|---|---|
The span must be in scope. |
The following listing shows integration tests that use baggage:
The setup.
spring.sleuth:
baggage-keys:
- baz
- bizarrecase
propagation-keys:
- foo
- upper_case
The code.
initialSpan.tag("foo", ExtraFieldPropagation.get(initialSpan.context(), "foo")); initialSpan.tag("UPPER_CASE", ExtraFieldPropagation.get(initialSpan.context(), "UPPER_CASE"));
This section addresses how to add Sleuth to your project with either Maven or Gradle.
| Important |
|---|---|
To ensure that your application name is properly displayed in Zipkin, set the |
If you want to use only Spring Cloud Sleuth without the Zipkin integration, add the spring-cloud-starter-sleuth module to your project.
The following example shows how to add Sleuth with Maven:
Maven.
<dependencyManagement><dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${release.train.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependency>
<groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
| We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| Add the dependency to |
The following example shows how to add Sleuth with Gradle:
Gradle.
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}
| We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| Add the dependency to |
If you want both Sleuth and Zipkin, add the spring-cloud-starter-zipkin dependency.
The following example shows how to do so for Maven:
Maven.
<dependencyManagement>
| We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| Add the dependency to |
The following example shows how to do so for Gradle:
Gradle.
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}
| We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| Add the dependency to |
If you want to use RabbitMQ or Kafka instead of HTTP, add the spring-rabbit or spring-kafka dependency.
The default destination name is zipkin.
If using Kafka, you must set the property spring.zipkin.sender.type property accordingly:
spring.zipkin.sender.type: kafka![[Caution]](images/caution.png) | Caution |
|---|---|
|
If you want Sleuth over RabbitMQ, add the spring-cloud-starter-zipkin and spring-rabbit
dependencies.
The following example shows how to do so for Gradle:
Maven.
<dependencyManagement><groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> </dependency>
| We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| Add the dependency to |
| To automatically configure RabbitMQ, add the |
Gradle.
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
compile "org.springframework.amqp:spring-rabbit"
}
| We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| Add the dependency to |
| To automatically configure RabbitMQ, add the |