2.2.2.RELEASE
This project provides Netflix OSS integrations for Spring Boot apps through autoconfiguration and binding to the Spring Environment and other Spring programming model idioms. With a few simple annotations you can quickly enable and configure the common patterns inside your application and build large distributed systems with battle-tested Netflix components. The patterns provided include Service Discovery (Eureka), Circuit Breaker (Hystrix), Intelligent Routing (Zuul) and Client Side Load Balancing (Ribbon).
1. Service Discovery: Eureka Clients
Service Discovery is one of the key tenets of a microservice-based architecture. Trying to hand-configure each client or some form of convention can be difficult to do and can be brittle. Eureka is the Netflix Service Discovery Server and Client. The server can be configured and deployed to be highly available, with each server replicating state about the registered services to the others.
1.1. How to Include Eureka Client
To include the Eureka Client in your project, use the starter with a group ID of org.springframework.cloud and an artifact ID of spring-cloud-starter-netflix-eureka-client.
See the Spring Cloud Project page for details on setting up your build system with the current Spring Cloud Release Train.
1.2. Registering with Eureka
When a client registers with Eureka, it provides meta-data about itself — such as host, port, health indicator URL, home page, and other details. Eureka receives heartbeat messages from each instance belonging to a service. If the heartbeat fails over a configurable timetable, the instance is normally removed from the registry.
The following example shows a minimal Eureka client application:
@SpringBootApplication
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}Note that the preceding example shows a normal Spring Boot application.
By having spring-cloud-starter-netflix-eureka-client on the classpath, your application automatically registers with the Eureka Server. Configuration is required to locate the Eureka server, as shown in the following example:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
In the preceding example, defaultZone is a magic string fallback value that provides the service URL for any client that does not express a preference (in other words, it is a useful default).
The defaultZone property is case sensitive and requires camel case because the serviceUrl property is a Map<String, String>. Therefore, the defaultZone property does not follow the normal Spring Boot snake-case convention of default-zone.
|
The default application name (that is, the service ID), virtual host, and non-secure port (taken from the Environment) are ${spring.application.name}, ${spring.application.name} and ${server.port}, respectively.
Having spring-cloud-starter-netflix-eureka-client on the classpath makes the app into both a Eureka “instance” (that is, it registers itself) and a “client” (it can query the registry to locate other services).
The instance behaviour is driven by eureka.instance.* configuration keys, but the defaults are fine if you ensure that your application has a value for spring.application.name (this is the default for the Eureka service ID or VIP).
See EurekaInstanceConfigBean and EurekaClientConfigBean for more details on the configurable options.
To disable the Eureka Discovery Client, you can set eureka.client.enabled to false. Eureka Discovery Client will also be disabled when spring.cloud.discovery.enabled is set to false.
1.3. Authenticating with the Eureka Server
HTTP basic authentication is automatically added to your eureka client if one of the eureka.client.serviceUrl.defaultZone URLs has credentials embedded in it (curl style, as follows: user:password@localhost:8761/eureka).
For more complex needs, you can create a @Bean of type DiscoveryClientOptionalArgs and inject ClientFilter instances into it, all of which is applied to the calls from the client to the server.
| Because of a limitation in Eureka, it is not possible to support per-server basic auth credentials, so only the first set that are found is used. |
1.4. Status Page and Health Indicator
The status page and health indicators for a Eureka instance default to /info and /health respectively, which are the default locations of useful endpoints in a Spring Boot Actuator application.
You need to change these, even for an Actuator application if you use a non-default context path or servlet path (such as server.servletPath=/custom). The following example shows the default values for the two settings:
eureka:
instance:
statusPageUrlPath: ${server.servletPath}/info
healthCheckUrlPath: ${server.servletPath}/health
These links show up in the metadata that is consumed by clients and are used in some scenarios to decide whether to send requests to your application, so it is helpful if they are accurate.
| In Dalston it was also required to set the status and health check URLs when changing that management context path. This requirement was removed beginning in Edgware. |
1.5. Registering a Secure Application
If your app wants to be contacted over HTTPS, you can set two flags in the EurekaInstanceConfig:
-
eureka.instance.[nonSecurePortEnabled]=[false] -
eureka.instance.[securePortEnabled]=[true]
Doing so makes Eureka publish instance information that shows an explicit preference for secure communication.
The Spring Cloud DiscoveryClient always returns a URI starting with https for a service configured this way.
Similarly, when a service is configured this way, the Eureka (native) instance information has a secure health check URL.
Because of the way Eureka works internally, it still publishes a non-secure URL for the status and home pages unless you also override those explicitly. You can use placeholders to configure the eureka instance URLs, as shown in the following example:
eureka:
instance:
statusPageUrl: https://${eureka.hostname}/info
healthCheckUrl: https://${eureka.hostname}/health
homePageUrl: https://${eureka.hostname}/
(Note that ${eureka.hostname} is a native placeholder only available
in later versions of Eureka. You could achieve the same thing with
Spring placeholders as well — for example, by using ${eureka.instance.hostName}.)
| If your application runs behind a proxy, and the SSL termination is in the proxy (for example, if you run in Cloud Foundry or other platforms as a service), then you need to ensure that the proxy “forwarded” headers are intercepted and handled by the application. If the Tomcat container embedded in a Spring Boot application has explicit configuration for the 'X-Forwarded-\*` headers, this happens automatically. The links rendered by your app to itself being wrong (the wrong host, port, or protocol) is a sign that you got this configuration wrong. |
1.6. Eureka’s Health Checks
By default, Eureka uses the client heartbeat to determine if a client is up. Unless specified otherwise, the Discovery Client does not propagate the current health check status of the application, per the Spring Boot Actuator. Consequently, after successful registration, Eureka always announces that the application is in 'UP' state. This behavior can be altered by enabling Eureka health checks, which results in propagating application status to Eureka. As a consequence, every other application does not send traffic to applications in states other then 'UP'. The following example shows how to enable health checks for the client:
eureka:
client:
healthcheck:
enabled: true
eureka.client.healthcheck.enabled=true should only be set in application.yml. Setting the value in bootstrap.yml causes undesirable side effects, such as registering in Eureka with an UNKNOWN status.
|
If you require more control over the health checks, consider implementing your own com.netflix.appinfo.HealthCheckHandler.
1.7. Eureka Metadata for Instances and Clients
It is worth spending a bit of time understanding how the Eureka metadata works, so you can use it in a way that makes sense in your platform.
There is standard metadata for information such as hostname, IP address, port numbers, the status page, and health check.
These are published in the service registry and used by clients to contact the services in a straightforward way.
Additional metadata can be added to the instance registration in the eureka.instance.metadataMap, and this metadata is accessible in the remote clients.
In general, additional metadata does not change the behavior of the client, unless the client is made aware of the meaning of the metadata.
There are a couple of special cases, described later in this document, where Spring Cloud already assigns meaning to the metadata map.
1.7.1. Using Eureka on Cloud Foundry
Cloud Foundry has a global router so that all instances of the same app have the same hostname (other PaaS solutions with a similar architecture have the same arrangement).
This is not necessarily a barrier to using Eureka.
However, if you use the router (recommended or even mandatory, depending on the way your platform was set up), you need to explicitly set the hostname and port numbers (secure or non-secure) so that they use the router.
You might also want to use instance metadata so that you can distinguish between the instances on the client (for example, in a custom load balancer).
By default, the eureka.instance.instanceId is vcap.application.instance_id, as shown in the following example:
eureka:
instance:
hostname: ${vcap.application.uris[0]}
nonSecurePort: 80
Depending on the way the security rules are set up in your Cloud Foundry instance, you might be able to register and use the IP address of the host VM for direct service-to-service calls. This feature is not yet available on Pivotal Web Services (PWS).
1.7.2. Using Eureka on AWS
If the application is planned to be deployed to an AWS cloud, the Eureka instance must be configured to be AWS-aware. You can do so by customizing the EurekaInstanceConfigBean as follows:
@Bean
@Profile("!default")
public EurekaInstanceConfigBean eurekaInstanceConfig(InetUtils inetUtils) {
EurekaInstanceConfigBean b = new EurekaInstanceConfigBean(inetUtils);
AmazonInfo info = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
b.setDataCenterInfo(info);
return b;
}1.7.3. Changing the Eureka Instance ID
A vanilla Netflix Eureka instance is registered with an ID that is equal to its host name (that is, there is only one service per host). Spring Cloud Eureka provides a sensible default, which is defined as follows:
${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance_id:${server.port}}}
An example is myhost:myappname:8080.
By using Spring Cloud, you can override this value by providing a unique identifier in eureka.instance.instanceId, as shown in the following example:
eureka:
instance:
instanceId: ${spring.application.name}:${vcap.application.instance_id:${spring.application.instance_id:${random.value}}}
With the metadata shown in the preceding example and multiple service instances deployed on localhost, the random value is inserted there to make the instance unique.
In Cloud Foundry, the vcap.application.instance_id is populated automatically in a Spring Boot application, so the random value is not needed.
1.8. Using the EurekaClient
Once you have an application that is a discovery client, you can use it to discover service instances from the Eureka Server.
One way to do so is to use the native com.netflix.discovery.EurekaClient (as opposed to the Spring Cloud DiscoveryClient), as shown in the following example:
@Autowired
private EurekaClient discoveryClient;
public String serviceUrl() {
InstanceInfo instance = discoveryClient.getNextServerFromEureka("STORES", false);
return instance.getHomePageUrl();
}
|
Do not use the |
1.8.1. EurekaClient without Jersey
By default, EurekaClient uses Jersey for HTTP communication.
If you wish to avoid dependencies from Jersey, you can exclude it from your dependencies.
Spring Cloud auto-configures a transport client based on Spring RestTemplate.
The following example shows Jersey being excluded:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<exclusions>
<exclusion>
<groupId>com.sun.jersey</groupId>
<artifactId>jersey-client</artifactId>
</exclusion>
<exclusion>
<groupId>com.sun.jersey</groupId>
<artifactId>jersey-core</artifactId>
</exclusion>
<exclusion>
<groupId>com.sun.jersey.contribs</groupId>
<artifactId>jersey-apache-client4</artifactId>
</exclusion>
</exclusions>
</dependency>
1.9. Alternatives to the Native Netflix EurekaClient
You need not use the raw Netflix EurekaClient.
Also, it is usually more convenient to use it behind a wrapper of some sort.
Spring Cloud has support for Feign (a REST client builder) and Spring RestTemplate through the logical Eureka service identifiers (VIPs) instead of physical URLs.
To configure Ribbon with a fixed list of physical servers, you can set <client>.ribbon.listOfServers to a comma-separated list of physical addresses (or hostnames), where <client> is the ID of the client.
You can also use the org.springframework.cloud.client.discovery.DiscoveryClient, which provides a simple API (not specific to Netflix) for discovery clients, as shown in the following example:
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
1.10. Why Is It so Slow to Register a Service?
Being an instance also involves a periodic heartbeat to the registry
(through the client’s serviceUrl) with a default duration of 30 seconds.
A service is not available for discovery by clients until the instance, the server, and the client all have the same metadata in their local
cache (so it could take 3 heartbeats).
You can change the period by setting eureka.instance.leaseRenewalIntervalInSeconds.
Setting it to a value of less than 30 speeds up the process of getting clients connected to other services.
In production, it is probably better to stick with the default, because of internal computations in the server that make assumptions about the lease renewal period.
1.11. Zones
If you have deployed Eureka clients to multiple zones, you may prefer that those clients use services within the same zone before trying services in another zone. To set that up, you need to configure your Eureka clients correctly.
First, you need to make sure you have Eureka servers deployed to each zone and that they are peers of each other. See the section on zones and regions for more information.
Next, you need to tell Eureka which zone your service is in.
You can do so by using the metadataMap property.
For example, if service 1 is deployed to both zone 1 and zone 2, you need to set the following Eureka properties in service 1:
Service 1 in Zone 1
eureka.instance.metadataMap.zone = zone1
eureka.client.preferSameZoneEureka = trueService 1 in Zone 2
eureka.instance.metadataMap.zone = zone2
eureka.client.preferSameZoneEureka = true1.12. Refreshing Eureka Clients
By default, the EurekaClient bean is refreshable, meaning the Eureka client properties can be changed and refreshed.
When a refresh occurs clients will be unregistered from the Eureka server and there might be a brief moment of time
where all instance of a given service are not available. One way to eliminate this from happening is to disable
the ability to refresh Eureka clients. To do this set eureka.client.refresh.enable=false.
1.13. Using Eureka with Spring Cloud LoadBalancer
We offer support for the Spring Cloud LoadBalancer ZonePreferenceServiceInstanceListSupplier.
The zone value from the Eureka instance metadata (eureka.instance.metadataMap.zone) is used for setting the
value of spring-clod-loadbalancer-zone property that is used to filter service instances by zone.
If that is missing and if the spring.cloud.loadbalancer.eureka.approximateZoneFromHostname flag is set to true,
it can use the domain name from the server hostname as a proxy for the zone.
If there is no other source of zone data, then a guess is made, based on the client configuration (as opposed to the instance configuration).
We take eureka.client.availabilityZones, which is a map from region name to a list of zones, and pull out the first zone for the instance’s own region (that is, the eureka.client.region, which defaults to "us-east-1", for compatibility with native Netflix).
2. Service Discovery: Eureka Server
This section describes how to set up a Eureka server.
2.1. How to Include Eureka Server
To include Eureka Server in your project, use the starter with a group ID of org.springframework.cloud and an artifact ID of spring-cloud-starter-netflix-eureka-server.
See the Spring Cloud Project page for details on setting up your build system with the current Spring Cloud Release Train.
| If your project already uses Thymeleaf as its template engine, the Freemarker templates of the Eureka server may not be loaded correctly. In this case it is necessary to configure the template loader manually: |
spring:
freemarker:
template-loader-path: classpath:/templates/
prefer-file-system-access: false
2.2. How to Run a Eureka Server
The following example shows a minimal Eureka server:
@SpringBootApplication
@EnableEurekaServer
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}The server has a home page with a UI and HTTP API endpoints for the normal Eureka functionality under /eureka/*.
The following links have some Eureka background reading: flux capacitor and google group discussion.
|
Due to Gradle’s dependency resolution rules and the lack of a parent bom feature, depending on build.gradle
|
2.3. High Availability, Zones and Regions
The Eureka server does not have a back end store, but the service instances in the registry all have to send heartbeats to keep their registrations up to date (so this can be done in memory). Clients also have an in-memory cache of Eureka registrations (so they do not have to go to the registry for every request to a service).
By default, every Eureka server is also a Eureka client and requires (at least one) service URL to locate a peer. If you do not provide it, the service runs and works, but it fills your logs with a lot of noise about not being able to register with the peer.
See also below for details of Ribbon support on the client side for Zones and Regions.
2.4. Standalone Mode
The combination of the two caches (client and server) and the heartbeats make a standalone Eureka server fairly resilient to failure, as long as there is some sort of monitor or elastic runtime (such as Cloud Foundry) keeping it alive. In standalone mode, you might prefer to switch off the client side behavior so that it does not keep trying and failing to reach its peers. The following example shows how to switch off the client-side behavior:
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
Notice that the serviceUrl is pointing to the same host as the local instance.
2.5. Peer Awareness
Eureka can be made even more resilient and available by running multiple instances and asking them to register with each other.
In fact, this is the default behavior, so all you need to do to make it work is add a valid serviceUrl to a peer, as shown in the following example:
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
client:
serviceUrl:
defaultZone: https://peer2/eureka/
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
client:
serviceUrl:
defaultZone: https://peer1/eureka/
In the preceding example, we have a YAML file that can be used to run the same server on two hosts (peer1 and peer2) by running it in different Spring profiles.
You could use this configuration to test the peer awareness on a single host (there is not much value in doing that in production) by manipulating /etc/hosts to resolve the host names.
In fact, the eureka.instance.hostname is not needed if you are running on a machine that knows its own hostname (by default, it is looked up by using java.net.InetAddress).
You can add multiple peers to a system, and, as long as they are all connected to each other by at least one edge, they synchronize the registrations amongst themselves. If the peers are physically separated (inside a data center or between multiple data centers), then the system can, in principle, survive “split-brain” type failures. You can add multiple peers to a system, and as long as they are all directly connected to each other, they will synchronize the registrations amongst themselves.
eureka:
client:
serviceUrl:
defaultZone: https://peer1/eureka/,http://peer2/eureka/,http://peer3/eureka/
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
---
spring:
profiles: peer3
eureka:
instance:
hostname: peer3
2.6. When to Prefer IP Address
In some cases, it is preferable for Eureka to advertise the IP addresses of services rather than the hostname.
Set eureka.instance.preferIpAddress to true and, when the application registers with eureka, it uses its IP address rather than its hostname.
|
If the hostname cannot be determined by Java, then the IP address is sent to Eureka.
Only explict way of setting the hostname is by setting |
2.7. Securing The Eureka Server
You can secure your Eureka server simply by adding Spring Security to your
server’s classpath via spring-boot-starter-security. By default when Spring Security is on the classpath it will require that
a valid CSRF token be sent with every request to the app. Eureka clients will not generally possess a valid
cross site request forgery (CSRF) token you will need to disable this requirement for the /eureka/** endpoints.
For example:
@EnableWebSecurity
class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().ignoringAntMatchers("/eureka/**");
super.configure(http);
}
}For more information on CSRF see the Spring Security documentation.
A demo Eureka Server can be found in the Spring Cloud Samples repo.
2.8. Disabling Ribbon with Eureka Server and Client starters
spring-cloud-starter-netflix-eureka-server and spring-cloud-starter-netflix-eureka-client come along with
a spring-cloud-starter-netflix-ribbon. Since Ribbon load-balancer is now in maintenance mode,
we suggest switching to using the Spring Cloud LoadBalancer, also included in Eureka starters, instead.
In order to that, you can set the value of spring.cloud.loadbalancer.ribbon.enabled property to false.
You can then also exclude ribbon-related dependencies from Eureka starters in your build files, like so:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
</exclusion>
<exclusion>
<groupId>com.netflix.ribbon</groupId>
<artifactId>ribbon-eureka</artifactId>
</exclusion>
</exclusions>
</dependency>2.9. JDK 11 Support
The JAXB modules which the Eureka server depends upon were removed in JDK 11. If you intend to use JDK 11 when running a Eureka server you must include these dependencies in your POM or Gradle file.
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
</dependency>3. Circuit Breaker: Spring Cloud Circuit Breaker With Hystrix
3.1. Disabling Spring Cloud Circuit Breaker Hystrix
You can disable the auto-configuration by setting spring.cloud.circuitbreaker.hystrix.enabled
to false.
3.2. Configuring Hystrix Circuit Breakers
3.2.1. Default Configuration
To provide a default configuration for all of your circuit breakers create a Customize bean that is passed a
HystrixCircuitBreakerFactory or ReactiveHystrixCircuitBreakerFactory.
The configureDefault method can be used to provide a default configuration.
@Bean
public Customizer<HystrixCircuitBreakerFactory> defaultConfig() {
return factory -> factory.configureDefault(id -> HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey(id))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(4000)));
}Reactive Example
@Bean
public Customizer<ReactiveHystrixCircuitBreakerFactory> defaultConfig() {
return factory -> factory.configureDefault(id -> HystrixObservableCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey(id))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(4000)));
}3.2.2. Specific Circuit Breaker Configuration
Similarly to providing a default configuration, you can create a Customize bean this is passed a
HystrixCircuitBreakerFactory
@Bean
public Customizer<HystrixCircuitBreakerFactory> customizer() {
return factory -> factory.configure(builder -> builder.commandProperties(
HystrixCommandProperties.Setter().withExecutionTimeoutInMilliseconds(2000)), "foo", "bar");
}Reactive Example
@Bean
public Customizer<ReactiveHystrixCircuitBreakerFactory> customizer() {
return factory -> factory.configure(builder -> builder.commandProperties(
HystrixCommandProperties.Setter().withExecutionTimeoutInMilliseconds(2000)), "foo", "bar");
}4. Circuit Breaker: Hystrix Clients
Netflix has created a library called Hystrix that implements the circuit breaker pattern. In a microservice architecture, it is common to have multiple layers of service calls, as shown in the following example:
A service failure in the lower level of services can cause cascading failure all the way up to the user.
When calls to a particular service exceed circuitBreaker.requestVolumeThreshold (default: 20 requests) and the failure percentage is greater than circuitBreaker.errorThresholdPercentage (default: >50%) in a rolling window defined by metrics.rollingStats.timeInMilliseconds (default: 10 seconds), the circuit opens and the call is not made.
In cases of error and an open circuit, a fallback can be provided by the developer.
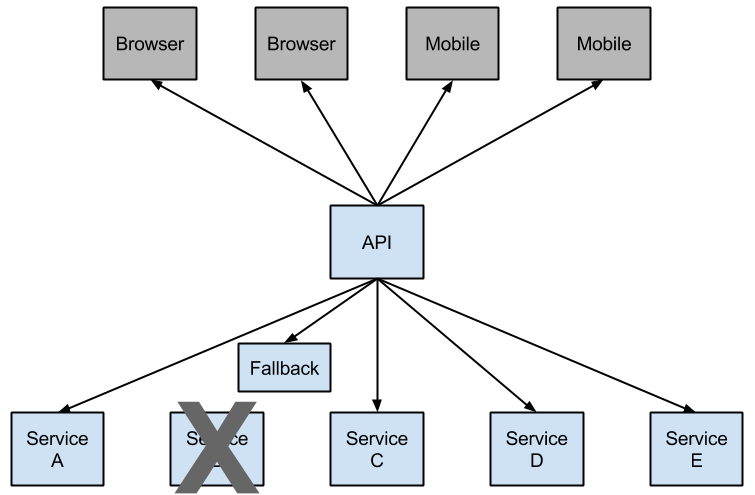
Having an open circuit stops cascading failures and allows overwhelmed or failing services time to recover. The fallback can be another Hystrix protected call, static data, or a sensible empty value. Fallbacks may be chained so that the first fallback makes some other business call, which in turn falls back to static data.
4.1. How to Include Hystrix
To include Hystrix in your project, use the starter with a group ID of org.springframework.cloud
and a artifact ID of spring-cloud-starter-netflix-hystrix.
See the Spring Cloud Project page for details on setting up your build system with the current Spring Cloud Release Train.
The following example shows a minimal Eureka server with a Hystrix circuit breaker:
@SpringBootApplication
@EnableCircuitBreaker
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
@Component
public class StoreIntegration {
@HystrixCommand(fallbackMethod = "defaultStores")
public Object getStores(Map<String, Object> parameters) {
//do stuff that might fail
}
public Object defaultStores(Map<String, Object> parameters) {
return /* something useful */;
}
}
The @HystrixCommand is provided by a Netflix contrib library called “javanica”.
Spring Cloud automatically wraps Spring beans with that annotation in a proxy that is connected to the Hystrix circuit breaker.
The circuit breaker calculates when to open and close the circuit and what to do in case of a failure.
To configure the @HystrixCommand you can use the commandProperties
attribute with a list of @HystrixProperty annotations. See
here
for more details. See the Hystrix wiki
for details on the properties available.
4.2. Propagating the Security Context or Using Spring Scopes
If you want some thread local context to propagate into a @HystrixCommand, the default declaration does not work, because it executes the command in a thread pool (in case of timeouts).
You can switch Hystrix to use the same thread as the caller through configuration or directly in the annotation, by asking it to use a different “Isolation Strategy”.
The following example demonstrates setting the thread in the annotation:
@HystrixCommand(fallbackMethod = "stubMyService",
commandProperties = {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")
}
)
...The same thing applies if you are using @SessionScope or @RequestScope.
If you encounter a runtime exception that says it cannot find the scoped context, you need to use the same thread.
You also have the option to set the hystrix.shareSecurityContext property to true.
Doing so auto-configures a Hystrix concurrency strategy plugin hook to transfer the SecurityContext from your main thread to the one used by the Hystrix command.
Hystrix does not let multiple Hystrix concurrency strategy be registered so an extension mechanism is available by declaring your own HystrixConcurrencyStrategy as a Spring bean.
Spring Cloud looks for your implementation within the Spring context and wrap it inside its own plugin.
4.3. Health Indicator
The state of the connected circuit breakers are also exposed in the /health endpoint of the calling application, as shown in the following example:
{
"hystrix": {
"openCircuitBreakers": [
"StoreIntegration::getStoresByLocationLink"
],
"status": "CIRCUIT_OPEN"
},
"status": "UP"
}4.4. Hystrix Metrics Stream
To enable the Hystrix metrics stream, include a dependency on spring-boot-starter-actuator and set
management.endpoints.web.exposure.include: hystrix.stream.
Doing so exposes the /actuator/hystrix.stream as a management endpoint, as shown in the following example:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>5. Circuit Breaker: Hystrix Dashboard
One of the main benefits of Hystrix is the set of metrics it gathers about each HystrixCommand. The Hystrix Dashboard displays the health of each circuit breaker in an efficient manner.
6. Hystrix Timeouts And Ribbon Clients
When using Hystrix commands that wrap Ribbon clients you want to make sure your Hystrix timeout is configured to be longer than the configured Ribbon timeout, including any potential retries that might be made. For example, if your Ribbon connection timeout is one second and the Ribbon client might retry the request three times, than your Hystrix timeout should be slightly more than three seconds.
6.1. How to Include the Hystrix Dashboard
To include the Hystrix Dashboard in your project, use the starter with a group ID of org.springframework.cloud and an artifact ID of spring-cloud-starter-netflix-hystrix-dashboard.
See the Spring Cloud Project page for details on setting up your build system with the current Spring Cloud Release Train.
To run the Hystrix Dashboard, annotate your Spring Boot main class with @EnableHystrixDashboard.
Then visit /hystrix and point the dashboard to an individual instance’s /hystrix.stream endpoint in a Hystrix client application.
When connecting to a /hystrix.stream endpoint that uses HTTPS, the certificate used by the server must be trusted by the JVM.
If the certificate is not trusted, you must import the certificate into the JVM in order for the Hystrix Dashboard to make a successful connection to the stream endpoint.
|
6.2. Turbine
Looking at an individual instance’s Hystrix data is not very useful in terms of the overall health of the system. Turbine is an application that aggregates all of the relevant /hystrix.stream endpoints into a combined /turbine.stream for use in the Hystrix Dashboard.
Individual instances are located through Eureka.
Running Turbine requires annotating your main class with the @EnableTurbine annotation (for example, by using spring-cloud-starter-netflix-turbine to set up the classpath).
All of the documented configuration properties from the Turbine 1 wiki apply.
The only difference is that the turbine.instanceUrlSuffix does not need the port prepended, as this is handled automatically unless turbine.instanceInsertPort=false.
By default, Turbine looks for the /hystrix.stream endpoint on a registered instance by looking up its hostName and port entries in Eureka and then appending /hystrix.stream to it.
If the instance’s metadata contains management.port, it is used instead of the port value for the /hystrix.stream endpoint.
By default, the metadata entry called management.port is equal to the management.port configuration property.
It can be overridden though with following configuration:
|
eureka:
instance:
metadata-map:
management.port: ${management.port:8081}
The turbine.appConfig configuration key is a list of Eureka serviceIds that turbine uses to lookup instances.
The turbine stream is then used in the Hystrix dashboard with a URL similar to the following:
The cluster parameter can be omitted if the name is default.
The cluster parameter must match an entry in turbine.aggregator.clusterConfig.
Values returned from Eureka are upper-case. Consequently, the following example works if there is an application called customers registered with Eureka:
turbine:
aggregator:
clusterConfig: CUSTOMERS
appConfig: customers
If you need to customize which cluster names should be used by Turbine (because you do not want to store cluster names in
turbine.aggregator.clusterConfig configuration), provide a bean of type TurbineClustersProvider.
The clusterName can be customized by a SPEL expression in turbine.clusterNameExpression with root as an instance of InstanceInfo.
The default value is appName, which means that the Eureka serviceId becomes the cluster key (that is, the InstanceInfo for customers has an appName of CUSTOMERS).
A different example is turbine.clusterNameExpression=aSGName, which gets the cluster name from the AWS ASG name.
The following listing shows another example:
turbine:
aggregator:
clusterConfig: SYSTEM,USER
appConfig: customers,stores,ui,admin
clusterNameExpression: metadata['cluster']
In the preceding example, the cluster name from four services is pulled from their metadata map and is expected to have values that include SYSTEM and USER.
To use the “default” cluster for all apps, you need a string literal expression (with single quotes and escaped with double quotes if it is in YAML as well):
turbine: appConfig: customers,stores clusterNameExpression: "'default'"
Spring Cloud provides a spring-cloud-starter-netflix-turbine that has all the dependencies you need to get a Turbine server running. To add Turbine, create a Spring Boot application and annotate it with @EnableTurbine.
By default, Spring Cloud lets Turbine use the host and port to allow multiple processes per host, per cluster.
If you want the native Netflix behavior built into Turbine to not allow multiple processes per host, per cluster (the key to the instance ID is the hostname), set turbine.combineHostPort=false.
|
6.2.1. Clusters Endpoint
In some situations it might be useful for other applications to know what custers have been configured
in Turbine. To support this you can use the /clusters endpoint which will return a JSON array of
all the configured clusters.
[
{
"name": "RACES",
"link": "http://localhost:8383/turbine.stream?cluster=RACES"
},
{
"name": "WEB",
"link": "http://localhost:8383/turbine.stream?cluster=WEB"
}
]This endpoint can be disabled by setting turbine.endpoints.clusters.enabled to false.
6.3. Turbine Stream
In some environments (such as in a PaaS setting), the classic Turbine model of pulling metrics from all the distributed Hystrix commands does not work.
In that case, you might want to have your Hystrix commands push metrics to Turbine. Spring Cloud enables that with messaging.
To do so on the client, add a dependency to spring-cloud-netflix-hystrix-stream and the spring-cloud-starter-stream-* of your choice.
See the Spring Cloud Stream documentation for details on the brokers and how to configure the client credentials. It should work out of the box for a local broker.
On the server side, create a Spring Boot application and annotate it with @EnableTurbineStream.
The Turbine Stream server requires the use of Spring Webflux, therefore spring-boot-starter-webflux needs to be included in your project.
By default spring-boot-starter-webflux is included when adding spring-cloud-starter-netflix-turbine-stream to your application.
You can then point the Hystrix Dashboard to the Turbine Stream Server instead of individual Hystrix streams.
If Turbine Stream is running on port 8989 on myhost, then put myhost:8989 in the stream input field in the Hystrix Dashboard.
Circuits are prefixed by their respective serviceId, followed by a dot (.), and then the circuit name.
Spring Cloud provides a spring-cloud-starter-netflix-turbine-stream that has all the dependencies you need to get a Turbine Stream server running.
You can then add the Stream binder of your choice — such as spring-cloud-starter-stream-rabbit.
Turbine Stream server also supports the cluster parameter.
Unlike Turbine server, Turbine Stream uses eureka serviceIds as cluster names and these are not configurable.
If Turbine Stream server is running on port 8989 on my.turbine.server and you have two eureka serviceIds customers and products in your environment, the following URLs will be available on your Turbine Stream server. default and empty cluster name will provide all metrics that Turbine Stream server receives.
https://my.turbine.sever:8989/turbine.stream?cluster=customers https://my.turbine.sever:8989/turbine.stream?cluster=products https://my.turbine.sever:8989/turbine.stream?cluster=default https://my.turbine.sever:8989/turbine.stream
So, you can use eureka serviceIds as cluster names for your Turbine dashboard (or any compatible dashboard).
You don’t need to configure any properties like turbine.appConfig, turbine.clusterNameExpression and turbine.aggregator.clusterConfig for your Turbine Stream server.
| Turbine Stream server gathers all metrics from the configured input channel with Spring Cloud Stream. It means that it doesn’t gather Hystrix metrics actively from each instance. It just can provide metrics that were already gathered into the input channel by each instance. |
7. Client Side Load Balancer: Ribbon
Ribbon is a client-side load balancer that gives you a lot of control over the behavior of HTTP and TCP clients.
Feign already uses Ribbon, so, if you use @FeignClient, this section also applies.
A central concept in Ribbon is that of the named client.
Each load balancer is part of an ensemble of components that work together to contact a remote server on demand, and the ensemble has a name that you give it as an application developer (for example, by using the @FeignClient annotation).
On demand, Spring Cloud creates a new ensemble as an ApplicationContext for each named client by using
RibbonClientConfiguration.
This contains (amongst other things) an ILoadBalancer, a RestClient, and a ServerListFilter.
7.1. How to Include Ribbon
To include Ribbon in your project, use the starter with a group ID of org.springframework.cloud and an artifact ID of spring-cloud-starter-netflix-ribbon.
See the Spring Cloud Project page for details on setting up your build system with the current Spring Cloud Release Train.
7.2. Customizing the Ribbon Client
You can configure some bits of a Ribbon client by using external properties in <client>.ribbon.*, which is similar to using the Netflix APIs natively, except that you can use Spring Boot configuration files.
The native options can be inspected as static fields in CommonClientConfigKey (part of ribbon-core).
Spring Cloud also lets you take full control of the client by declaring additional configuration (on top of the RibbonClientConfiguration) using @RibbonClient, as shown in the following example:
@Configuration
@RibbonClient(name = "custom", configuration = CustomConfiguration.class)
public class TestConfiguration {
}In this case, the client is composed from the components already in RibbonClientConfiguration, together with any in CustomConfiguration (where the latter generally overrides the former).
The CustomConfiguration class must be a @Configuration class, but take care that it is not in a @ComponentScan for the main application context.
Otherwise, it is shared by all the @RibbonClients. If you use @ComponentScan (or @SpringBootApplication), you need to take steps to avoid it being included (for instance, you can put it in a separate, non-overlapping package or specify the packages to scan explicitly in the @ComponentScan).
|
The following table shows the beans that Spring Cloud Netflix provides by default for Ribbon:
| Bean Type | Bean Name | Class Name |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Creating a bean of one of those type and placing it in a @RibbonClient configuration (such as FooConfiguration above) lets you override each one of the beans described, as shown in the following example:
@Configuration(proxyBeanMethods = false)
protected static class FooConfiguration {
@Bean
public ZonePreferenceServerListFilter serverListFilter() {
ZonePreferenceServerListFilter filter = new ZonePreferenceServerListFilter();
filter.setZone("myTestZone");
return filter;
}
@Bean
public IPing ribbonPing() {
return new PingUrl();
}
}The include statement in the preceding example replaces NoOpPing with PingUrl and provides a custom serverListFilter.
7.3. Customizing the Default for All Ribbon Clients
A default configuration can be provided for all Ribbon Clients by using the @RibbonClients annotation and registering a default configuration, as shown in the following example:
@RibbonClients(defaultConfiguration = DefaultRibbonConfig.class)
public class RibbonClientDefaultConfigurationTestsConfig {
public static class BazServiceList extends ConfigurationBasedServerList {
public BazServiceList(IClientConfig config) {
super.initWithNiwsConfig(config);
}
}
}
@Configuration(proxyBeanMethods = false)
class DefaultRibbonConfig {
@Bean
public IRule ribbonRule() {
return new BestAvailableRule();
}
@Bean
public IPing ribbonPing() {
return new PingUrl();
}
@Bean
public ServerList<Server> ribbonServerList(IClientConfig config) {
return new RibbonClientDefaultConfigurationTestsConfig.BazServiceList(config);
}
@Bean
public ServerListSubsetFilter serverListFilter() {
ServerListSubsetFilter filter = new ServerListSubsetFilter();
return filter;
}
}7.4. Customizing the Ribbon Client by Setting Properties
Starting with version 1.2.0, Spring Cloud Netflix now supports customizing Ribbon clients by setting properties to be compatible with the Ribbon documentation.
This lets you change behavior at start up time in different environments.
The following list shows the supported properties>:
-
<clientName>.ribbon.NFLoadBalancerClassName: Should implementILoadBalancer -
<clientName>.ribbon.NFLoadBalancerRuleClassName: Should implementIRule -
<clientName>.ribbon.NFLoadBalancerPingClassName: Should implementIPing -
<clientName>.ribbon.NIWSServerListClassName: Should implementServerList -
<clientName>.ribbon.NIWSServerListFilterClassName: Should implementServerListFilter
Classes defined in these properties have precedence over beans defined by using @RibbonClient(configuration=MyRibbonConfig.class) and the defaults provided by Spring Cloud Netflix.
|
To set the IRule for a service name called users, you could set the following properties:
users:
ribbon:
NIWSServerListClassName: com.netflix.loadbalancer.ConfigurationBasedServerList
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule
See the Ribbon documentation for implementations provided by Ribbon.
7.5. Using Ribbon with Eureka
When Eureka is used in conjunction with Ribbon (that is, both are on the classpath), the ribbonServerList is overridden with an extension of DiscoveryEnabledNIWSServerList, which populates the list of servers from Eureka.
It also replaces the IPing interface with NIWSDiscoveryPing, which delegates to Eureka to determine if a server is up.
The ServerList that is installed by default is a DomainExtractingServerList. Its purpose is to make metadata available to the load balancer without using AWS AMI metadata (which is what Netflix relies on).
By default, the server list is constructed with “zone” information, as provided in the instance metadata (so, on the remote clients, set eureka.instance.metadataMap.zone).
If that is missing and if the approximateZoneFromHostname flag is set, it can use the domain name from the server hostname as a proxy for the zone.
Once the zone information is available, it can be used in a ServerListFilter.
By default, it is used to locate a server in the same zone as the client, because the default is a ZonePreferenceServerListFilter.
By default, the zone of the client is determined in the same way as the remote instances (that is, through eureka.instance.metadataMap.zone).
| The orthodox “archaius” way to set the client zone is through a configuration property called "@zone". If it is available, Spring Cloud uses that in preference to all other settings (note that the key must be quoted in YAML configuration). |
If there is no other source of zone data, then a guess is made, based on the client configuration (as opposed to the instance configuration).
We take eureka.client.availabilityZones, which is a map from region name to a list of zones, and pull out the first zone for the instance’s own region (that is, the eureka.client.region, which defaults to "us-east-1", for compatibility with native Netflix).
|
7.6. Example: How to Use Ribbon Without Eureka
Eureka is a convenient way to abstract the discovery of remote servers so that you do not have to hard code their URLs in clients.
However, if you prefer not to use Eureka, Ribbon and Feign also work.
Suppose you have declared a @RibbonClient for "stores", and Eureka is not in use (and not even on the classpath).
The Ribbon client defaults to a configured server list.
You can supply the configuration as follows:
stores:
ribbon:
listOfServers: example.com,google.com
7.7. Example: Disable Eureka Use in Ribbon
Setting the ribbon.eureka.enabled property to false explicitly disables the use of Eureka in Ribbon, as shown in the following example:
ribbon: eureka: enabled: false
7.8. Using the Ribbon API Directly
You can also use the LoadBalancerClient directly, as shown in the following example:
public class MyClass {
@Autowired
private LoadBalancerClient loadBalancer;
public void doStuff() {
ServiceInstance instance = loadBalancer.choose("stores");
URI storesUri = URI.create(String.format("https://%s:%s", instance.getHost(), instance.getPort()));
// ... do something with the URI
}
}7.9. Caching of Ribbon Configuration
Each Ribbon named client has a corresponding child application Context that Spring Cloud maintains. This application context is lazily loaded on the first request to the named client. This lazy loading behavior can be changed to instead eagerly load these child application contexts at startup, by specifying the names of the Ribbon clients, as shown in the following example:
ribbon:
eager-load:
enabled: true
clients: client1, client2, client3
7.10. How to Configure Hystrix Thread Pools
If you change zuul.ribbonIsolationStrategy to THREAD, the thread isolation strategy for Hystrix is used for all routes.
In that case, the HystrixThreadPoolKey is set to RibbonCommand as the default.
It means that HystrixCommands for all routes are executed in the same Hystrix thread pool.
This behavior can be changed with the following configuration:
zuul:
threadPool:
useSeparateThreadPools: true
The preceding example results in HystrixCommands being executed in the Hystrix thread pool for each route.
In this case, the default HystrixThreadPoolKey is the same as the service ID for each route.
To add a prefix to HystrixThreadPoolKey, set zuul.threadPool.threadPoolKeyPrefix to the value that you want to add, as shown in the following example:
zuul:
threadPool:
useSeparateThreadPools: true
threadPoolKeyPrefix: zuulgw
7.11. How to Provide a Key to Ribbon’s IRule
If you need to provide your own IRule implementation to handle a special routing requirement like a “canary” test, pass some information to the choose method of IRule.
public interface IRule{
public Server choose(Object key);
:
You can provide some information that is used by your IRule implementation to choose a target server, as shown in the following example:
RequestContext.getCurrentContext()
.set(FilterConstants.LOAD_BALANCER_KEY, "canary-test");
If you put any object into the RequestContext with a key of FilterConstants.LOAD_BALANCER_KEY, it is passed to the choose method of the IRule implementation.
The code shown in the preceding example must be executed before RibbonRoutingFilter is executed.
Zuul’s pre filter is the best place to do that.
You can access HTTP headers and query parameters through the RequestContext in pre filter, so it can be used to determine the LOAD_BALANCER_KEY that is passed to Ribbon.
If you do not put any value with LOAD_BALANCER_KEY in RequestContext, null is passed as a parameter of the choose method.
8. External Configuration: Archaius
Archaius is the Netflix client-side configuration library. It is the library used by all of the Netflix OSS components for configuration. Archaius is an extension of the Apache Commons Configuration project. It allows updates to configuration by either polling a source for changes or by letting a source push changes to the client. Archaius uses Dynamic<Type>Property classes as handles to properties, as shown in the following example:
class ArchaiusTest {
DynamicStringProperty myprop = DynamicPropertyFactory
.getInstance()
.getStringProperty("my.prop");
void doSomething() {
OtherClass.someMethod(myprop.get());
}
}Archaius has its own set of configuration files and loading priorities. Spring applications should generally not use Archaius directly, but the need to configure the Netflix tools natively remains. Spring Cloud has a Spring Environment Bridge so that Archaius can read properties from the Spring Environment. This bridge allows Spring Boot projects to use the normal configuration toolchain while letting them configure the Netflix tools as documented (for the most part).
9. Router and Filter: Zuul
Routing is an integral part of a microservice architecture.
For example, / may be mapped to your web application, /api/users is mapped to the user service and /api/shop is mapped to the shop service.
Zuul is a JVM-based router and server-side load balancer from Netflix.
Netflix uses Zuul for the following:
-
Authentication
-
Insights
-
Stress Testing
-
Canary Testing
-
Dynamic Routing
-
Service Migration
-
Load Shedding
-
Security
-
Static Response handling
-
Active/Active traffic management
Zuul’s rule engine lets rules and filters be written in essentially any JVM language, with built-in support for Java and Groovy.
The configuration property zuul.max.host.connections has been replaced by two new properties, zuul.host.maxTotalConnections and zuul.host.maxPerRouteConnections, which default to 200 and 20 respectively.
|
The default Hystrix isolation pattern (ExecutionIsolationStrategy) for all routes is SEMAPHORE.
zuul.ribbonIsolationStrategy can be changed to THREAD if that isolation pattern is preferred.
|
9.1. How to Include Zuul
To include Zuul in your project, use the starter with a group ID of org.springframework.cloud and a artifact ID of spring-cloud-starter-netflix-zuul.
See the Spring Cloud Project page for details on setting up your build system with the current Spring Cloud Release Train.
9.2. Embedded Zuul Reverse Proxy
Spring Cloud has created an embedded Zuul proxy to ease the development of a common use case where a UI application wants to make proxy calls to one or more back end services. This feature is useful for a user interface to proxy to the back end services it requires, avoiding the need to manage CORS and authentication concerns independently for all the back ends.
To enable it, annotate a Spring Boot main class with @EnableZuulProxy. Doing so causes local calls to be forwarded to the appropriate service.
By convention, a service with an ID of users receives requests from the proxy located at /users (with the prefix stripped).
The proxy uses Ribbon to locate an instance to which to forward through discovery.
All requests are executed in a hystrix command, so failures appear in Hystrix metrics.
Once the circuit is open, the proxy does not try to contact the service.
| the Zuul starter does not include a discovery client, so, for routes based on service IDs, you need to provide one of those on the classpath as well (Eureka is one choice). |
To skip having a service automatically added, set zuul.ignored-services to a list of service ID patterns.
If a service matches a pattern that is ignored but is also included in the explicitly configured routes map, it is unignored, as shown in the following example:
zuul:
ignoredServices: '*'
routes:
users: /myusers/**In the preceding example, all services are ignored, except for users.
To augment or change the proxy routes, you can add external configuration, as follows:
zuul:
routes:
users: /myusers/**The preceding example means that HTTP calls to /myusers get forwarded to the users service (for example /myusers/101 is forwarded to /101).
To get more fine-grained control over a route, you can specify the path and the serviceId independently, as follows:
zuul:
routes:
users:
path: /myusers/**
serviceId: users_serviceThe preceding example means that HTTP calls to /myusers get forwarded to the users_service service.
The route must have a path that can be specified as an ant-style pattern, so /myusers/* only matches one level, but /myusers/** matches hierarchically.
The location of the back end can be specified as either a serviceId (for a service from discovery) or a url (for a physical location), as shown in the following example:
zuul:
routes:
users:
path: /myusers/**
url: https://example.com/users_serviceThese simple url-routes do not get executed as a HystrixCommand, nor do they load-balance multiple URLs with Ribbon.
To achieve those goals, you can specify a serviceId with a static list of servers, as follows:
zuul:
routes:
echo:
path: /myusers/**
serviceId: myusers-service
stripPrefix: true
hystrix:
command:
myusers-service:
execution:
isolation:
thread:
timeoutInMilliseconds: ...
myusers-service:
ribbon:
NIWSServerListClassName: com.netflix.loadbalancer.ConfigurationBasedServerList
listOfServers: https://example1.com,http://example2.com
ConnectTimeout: 1000
ReadTimeout: 3000
MaxTotalHttpConnections: 500
MaxConnectionsPerHost: 100Another method is specifiying a service-route and configuring a Ribbon client for the serviceId (doing so requires disabling Eureka support in Ribbon — see above for more information), as shown in the following example:
zuul:
routes:
users:
path: /myusers/**
serviceId: users
ribbon:
eureka:
enabled: false
users:
ribbon:
listOfServers: example.com,google.comYou can provide a convention between serviceId and routes by using regexmapper.
It uses regular-expression named groups to extract variables from serviceId and inject them into a route pattern, as shown in the following example:
@Bean
public PatternServiceRouteMapper serviceRouteMapper() {
return new PatternServiceRouteMapper(
"(?<name>^.+)-(?<version>v.+$)",
"${version}/${name}");
}The preceding example means that a serviceId of myusers-v1 is mapped to route /v1/myusers/**.
Any regular expression is accepted, but all named groups must be present in both servicePattern and routePattern.
If servicePattern does not match a serviceId, the default behavior is used.
In the preceding example, a serviceId of myusers is mapped to the "/myusers/**" route (with no version detected).
This feature is disabled by default and only applies to discovered services.
To add a prefix to all mappings, set zuul.prefix to a value, such as /api.
By default, the proxy prefix is stripped from the request before the request is forwarded by (you can switch this behavior off with zuul.stripPrefix=false).
You can also switch off the stripping of the service-specific prefix from individual routes, as shown in the following example:
zuul:
routes:
users:
path: /myusers/**
stripPrefix: false
zuul.stripPrefix only applies to the prefix set in zuul.prefix.
It does not have any effect on prefixes defined within a given route’s path.
|
In the preceding example, requests to /myusers/101 are forwarded to /myusers/101 on the users service.
The zuul.routes entries actually bind to an object of type ZuulProperties.
If you look at the properties of that object, you can see that it also has a retryable flag.
Set that flag to true to have the Ribbon client automatically retry failed requests.
You can also set that flag to true when you need to modify the parameters of the retry operations that use the Ribbon client configuration.
By default, the X-Forwarded-Host header is added to the forwarded requests.
To turn it off, set zuul.addProxyHeaders = false.
By default, the prefix path is stripped, and the request to the back end picks up a X-Forwarded-Prefix header (/myusers in the examples shown earlier).
If you set a default route (/), an application with @EnableZuulProxy could act as a standalone server. For example, zuul.route.home: / would route all traffic ("/**") to the "home" service.
If more fine-grained ignoring is needed, you can specify specific patterns to ignore. These patterns are evaluated at the start of the route location process, which means prefixes should be included in the pattern to warrant a match. Ignored patterns span all services and supersede any other route specification. The following example shows how to create ignored patterns:
zuul:
ignoredPatterns: /**/admin/**
routes:
users: /myusers/**The preceding example means that all calls (such as /myusers/101) are forwarded to /101 on the users service.
However, calls including /admin/ do not resolve.
| If you need your routes to have their order preserved, you need to use a YAML file, as the ordering is lost when using a properties file. The following example shows such a YAML file: |
zuul:
routes:
users:
path: /myusers/**
legacy:
path: /**If you were to use a properties file, the legacy path might end up in front of the users
path, rendering the users path unreachable.
9.3. Zuul Http Client
The default HTTP client used by Zuul is now backed by the Apache HTTP Client instead of the deprecated Ribbon RestClient.
To use RestClient or okhttp3.OkHttpClient, set ribbon.restclient.enabled=true or ribbon.okhttp.enabled=true, respectively.
If you would like to customize the Apache HTTP client or the OK HTTP client, provide a bean of type CloseableHttpClient or OkHttpClient.
9.4. Cookies and Sensitive Headers
You can share headers between services in the same system, but you probably do not want sensitive headers leaking downstream into external servers. You can specify a list of ignored headers as part of the route configuration. Cookies play a special role, because they have well defined semantics in browsers, and they are always to be treated as sensitive. If the consumer of your proxy is a browser, then cookies for downstream services also cause problems for the user, because they all get jumbled up together (all downstream services look like they come from the same place).
If you are careful with the design of your services, (for example, if only one of the downstream services sets cookies), you might be able to let them flow from the back end all the way up to the caller.
Also, if your proxy sets cookies and all your back-end services are part of the same system, it can be natural to simply share them (and, for instance, use Spring Session to link them up to some shared state).
Other than that, any cookies that get set by downstream services are likely to be not useful to the caller, so it is recommended that you make (at least) Set-Cookie and Cookie into sensitive headers for routes that are not part of your domain.
Even for routes that are part of your domain, try to think carefully about what it means before letting cookies flow between them and the proxy.
The sensitive headers can be configured as a comma-separated list per route, as shown in the following example:
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders: Cookie,Set-Cookie,Authorization
url: https://downstream
This is the default value for sensitiveHeaders, so you need not set it unless you want it to be different.
This is new in Spring Cloud Netflix 1.1 (in 1.0, the user had no control over headers, and all cookies flowed in both directions).
|
The sensitiveHeaders are a blacklist, and the default is not empty.
Consequently, to make Zuul send all headers (except the ignored ones), you must explicitly set it to the empty list.
Doing so is necessary if you want to pass cookie or authorization headers to your back end. The following example shows how to use sensitiveHeaders:
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders:
url: https://downstreamYou can also set sensitive headers, by setting zuul.sensitiveHeaders.
If sensitiveHeaders is set on a route, it overrides the global sensitiveHeaders setting.
9.5. Ignored Headers
In addition to the route-sensitive headers, you can set a global value called zuul.ignoredHeaders for values (both request and response) that should be discarded during interactions with downstream services.
By default, if Spring Security is not on the classpath, these are empty.
Otherwise, they are initialized to a set of well known “security” headers (for example, involving caching) as specified by Spring Security.
The assumption in this case is that the downstream services might add these headers, too, but we want the values from the proxy.
To not discard these well known security headers when Spring Security is on the classpath, you can set zuul.ignoreSecurityHeaders to false.
Doing so can be useful if you disabled the HTTP Security response headers in Spring Security and want the values provided by downstream services.
9.6. Management Endpoints
By default, if you use @EnableZuulProxy with the Spring Boot Actuator, you enable two additional endpoints:
-
Routes
-
Filters
9.6.1. Routes Endpoint
A GET to the routes endpoint at /routes returns a list of the mapped routes:
{
/stores/**: "http://localhost:8081"
}Additional route details can be requested by adding the ?format=details query string to /routes.
Doing so produces the following output:
{
"/stores/**": {
"id": "stores",
"fullPath": "/stores/**",
"location": "http://localhost:8081",
"path": "/**",
"prefix": "/stores",
"retryable": false,
"customSensitiveHeaders": false,
"prefixStripped": true
}
}A POST to /routes forces a refresh of the existing routes (for example, when there have been changes in the service catalog).
You can disable this endpoint by setting endpoints.routes.enabled to false.
the routes should respond automatically to changes in the service catalog, but the POST to /routes is a way to force the change
to happen immediately.
|
9.6.2. Filters Endpoint
A GET to the filters endpoint at /filters returns a map of Zuul filters by type.
For each filter type in the map, you get a list of all the filters of that type, along with their details.
9.7. Strangulation Patterns and Local Forwards
A common pattern when migrating an existing application or API is to “strangle” old endpoints, slowly replacing them with different implementations. The Zuul proxy is a useful tool for this because you can use it to handle all traffic from the clients of the old endpoints but redirect some of the requests to new ones.
The following example shows the configuration details for a “strangle” scenario:
zuul:
routes:
first:
path: /first/**
url: https://first.example.com
second:
path: /second/**
url: forward:/second
third:
path: /third/**
url: forward:/3rd
legacy:
path: /**
url: https://legacy.example.comIn the preceding example, we are strangle the “legacy” application, which is mapped to all requests that do not match one of the other patterns.
Paths in /first/** have been extracted into a new service with an external URL.
Paths in /second/** are forwarded so that they can be handled locally (for example, with a normal Spring @RequestMapping).
Paths in /third/** are also forwarded but with a different prefix (/third/foo is forwarded to /3rd/foo).
| The ignored patterns aren’t completely ignored, they just are not handled by the proxy (so they are also effectively forwarded locally). |
9.8. Uploading Files through Zuul
If you use @EnableZuulProxy, you can use the proxy paths to upload files and it should work, so long as the files are small.
For large files there is an alternative path that bypasses the Spring DispatcherServlet (to avoid multipart processing) in "/zuul/*".
In other words, if you have zuul.routes.customers=/customers/**, then you can POST large files to /zuul/customers/*.
The servlet path is externalized via zuul.servletPath.
If the proxy route takes you through a Ribbon load balancer, extremely large files also require elevated timeout settings, as shown in the following example:
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000Note that, for streaming to work with large files, you need to use chunked encoding in the request (which some browsers do not do by default), as shown in the following example:
$ curl -v -H "Transfer-Encoding: chunked" \
-F "[email protected]" localhost:9999/zuul/simple/file9.9. Query String Encoding
When processing the incoming request, query params are decoded so that they can be available for possible modifications in Zuul filters.
They are then re-encoded the back end request is rebuilt in the route filters.
The result can be different than the original input if (for example) it was encoded with Javascript’s encodeURIComponent() method.
While this causes no issues in most cases, some web servers can be picky with the encoding of complex query string.
To force the original encoding of the query string, it is possible to pass a special flag to ZuulProperties so that the query string is taken as is with the HttpServletRequest::getQueryString method, as shown in the following example:
zuul:
forceOriginalQueryStringEncoding: true
This special flag works only with SimpleHostRoutingFilter. Also, you loose the ability to easily override
query parameters with RequestContext.getCurrentContext().setRequestQueryParams(someOverriddenParameters), because
the query string is now fetched directly on the original HttpServletRequest.
|
9.10. Request URI Encoding
When processing the incoming request, request URI is decoded before matching them to routes. The request URI is then re-encoded when the back end request is rebuilt in the route filters. This can cause some unexpected behavior if your URI includes the encoded "/" character.
To use the original request URI, it is possible to pass a special flag to 'ZuulProperties' so that the URI will be taken as is with the HttpServletRequest::getRequestURI method, as shown in the following example:
zuul:
decodeUrl: false
If you are overriding request URI using requestURI RequestContext attribute and this flag is set to false, then the URL set in the request context will not be encoded. It will be your responsibility to make sure the URL is already encoded.
|
9.11. Plain Embedded Zuul
If you use @EnableZuulServer (instead of @EnableZuulProxy), you can also run a Zuul server without proxying or selectively switch on parts of the proxying platform.
Any beans that you add to the application of type ZuulFilter are installed automatically (as they are with @EnableZuulProxy) but without any of the proxy filters being added automatically.
In that case, the routes into the Zuul server are still specified by configuring "zuul.routes.*", but there is no service discovery and no proxying. Consequently, the "serviceId" and "url" settings are ignored. The following example maps all paths in "/api/**" to the Zuul filter chain:
zuul:
routes:
api: /api/**9.12. Disable Zuul Filters
Zuul for Spring Cloud comes with a number of ZuulFilter beans enabled by default in both proxy and server mode.
See the Zuul filters package for the list of filters that you can enable.
If you want to disable one, set zuul.<SimpleClassName>.<filterType>.disable=true.
By convention, the package after filters is the Zuul filter type.
For example to disable org.springframework.cloud.netflix.zuul.filters.post.SendResponseFilter, set zuul.SendResponseFilter.post.disable=true.
9.13. Providing Hystrix Fallbacks For Routes
When a circuit for a given route in Zuul is tripped, you can provide a fallback response by creating a bean of type FallbackProvider.
Within this bean, you need to specify the route ID the fallback is for and provide a ClientHttpResponse to return as a fallback.
The following example shows a relatively simple FallbackProvider implementation:
class MyFallbackProvider implements FallbackProvider {
@Override
public String getRoute() {
return "customers";
}
@Override
public ClientHttpResponse fallbackResponse(String route, final Throwable cause) {
if (cause instanceof HystrixTimeoutException) {
return response(HttpStatus.GATEWAY_TIMEOUT);
} else {
return response(HttpStatus.INTERNAL_SERVER_ERROR);
}
}
private ClientHttpResponse response(final HttpStatus status) {
return new ClientHttpResponse() {
@Override
public HttpStatus getStatusCode() throws IOException {
return status;
}
@Override
public int getRawStatusCode() throws IOException {
return status.value();
}
@Override
public String getStatusText() throws IOException {
return status.getReasonPhrase();
}
@Override
public void close() {
}
@Override
public InputStream getBody() throws IOException {
return new ByteArrayInputStream("fallback".getBytes());
}
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
};
}
}The following example shows how the route configuration for the previous example might appear:
zuul:
routes:
customers: /customers/**If you would like to provide a default fallback for all routes, you can create a bean of type FallbackProvider and have the getRoute method return * or null, as shown in the following example:
class MyFallbackProvider implements FallbackProvider {
@Override
public String getRoute() {
return "*";
}
@Override
public ClientHttpResponse fallbackResponse(String route, Throwable throwable) {
return new ClientHttpResponse() {
@Override
public HttpStatus getStatusCode() throws IOException {
return HttpStatus.OK;
}
@Override
public int getRawStatusCode() throws IOException {
return 200;
}
@Override
public String getStatusText() throws IOException {
return "OK";
}
@Override
public void close() {
}
@Override
public InputStream getBody() throws IOException {
return new ByteArrayInputStream("fallback".getBytes());
}
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
};
}
}9.14. Zuul Timeouts
If you want to configure the socket timeouts and read timeouts for requests proxied through Zuul, you have two options, based on your configuration:
-
If Zuul uses service discovery, you need to configure these timeouts with the
ribbon.ReadTimeoutandribbon.SocketTimeoutRibbon properties.
If you have configured Zuul routes by specifying URLs, you need to use
zuul.host.connect-timeout-millis and zuul.host.socket-timeout-millis.
9.15. Rewriting the Location header
If Zuul is fronting a web application, you may need to re-write the Location header when the web application redirects through a HTTP status code of 3XX.
Otherwise, the browser redirects to the web application’s URL instead of the Zuul URL.
You can configure a LocationRewriteFilter Zuul filter to re-write the Location header to the Zuul’s URL.
It also adds back the stripped global and route-specific prefixes.
The following example adds a filter by using a Spring Configuration file:
import org.springframework.cloud.netflix.zuul.filters.post.LocationRewriteFilter;
...
@Configuration
@EnableZuulProxy
public class ZuulConfig {
@Bean
public LocationRewriteFilter locationRewriteFilter() {
return new LocationRewriteFilter();
}
}
Use this filter carefully. The filter acts on the Location header of ALL 3XX response codes, which may not be appropriate in all scenarios, such as when redirecting the user to an external URL.
|
9.16. Enabling Cross Origin Requests
By default Zuul routes all Cross Origin requests (CORS) to the services. If you want instead Zuul to handle these requests it can be done by providing custom WebMvcConfigurer bean:
@Bean
public WebMvcConfigurer corsConfigurer() {
return new WebMvcConfigurer() {
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/path-1/**")
.allowedOrigins("https://allowed-origin.com")
.allowedMethods("GET", "POST");
}
};
}In the example above, we allow GET and POST methods from allowed-origin.com to send cross-origin requests to the endpoints starting with path-1.
You can apply CORS configuration to a specific path pattern or globally for the whole application, using /** mapping.
You can customize properties: allowedOrigins,allowedMethods,allowedHeaders,exposedHeaders,allowCredentials and maxAge via this configuration.
9.17. Metrics
Zuul will provide metrics under the Actuator metrics endpoint for any failures that might occur when routing requests.
These metrics can be viewed by hitting /actuator/metrics. The metrics will have a name that has the format
ZUUL::EXCEPTION:errorCause:statusCode.
9.18. Zuul Developer Guide
For a general overview of how Zuul works, see the Zuul Wiki.
9.18.1. The Zuul Servlet
Zuul is implemented as a Servlet. For the general cases, Zuul is embedded into the Spring Dispatch mechanism. This lets Spring MVC be in control of the routing.
In this case, Zuul buffers requests.
If there is a need to go through Zuul without buffering requests (for example, for large file uploads), the Servlet is also installed outside of the Spring Dispatcher.
By default, the servlet has an address of /zuul.
This path can be changed with the zuul.servlet-path property.
9.18.2. Zuul RequestContext
To pass information between filters, Zuul uses a RequestContext.
Its data is held in a ThreadLocal specific to each request.
Information about where to route requests, errors, and the actual HttpServletRequest and HttpServletResponse are stored there.
The RequestContext extends ConcurrentHashMap, so anything can be stored in the context. FilterConstants contains the keys used by the filters installed by Spring Cloud Netflix (more on these later).
9.18.3. @EnableZuulProxy vs. @EnableZuulServer
Spring Cloud Netflix installs a number of filters, depending on which annotation was used to enable Zuul. @EnableZuulProxy is a superset of @EnableZuulServer. In other words, @EnableZuulProxy contains all the filters installed by @EnableZuulServer. The additional filters in the “proxy” enable routing functionality. If you want a “blank” Zuul, you should use @EnableZuulServer.
9.18.4. @EnableZuulServer Filters
@EnableZuulServer creates a SimpleRouteLocator that loads route definitions from Spring Boot configuration files.
The following filters are installed (as normal Spring Beans):
-
Pre filters:
-
ServletDetectionFilter: Detects whether the request is through the Spring Dispatcher. Sets a boolean with a key ofFilterConstants.IS_DISPATCHER_SERVLET_REQUEST_KEY. -
FormBodyWrapperFilter: Parses form data and re-encodes it for downstream requests. -
DebugFilter: If thedebugrequest parameter is set, setsRequestContext.setDebugRouting()andRequestContext.setDebugRequest()totrue.
-
-
Route filters:
-
SendForwardFilter: Forwards requests by using the ServletRequestDispatcher. The forwarding location is stored in theRequestContextattribute,FilterConstants.FORWARD_TO_KEY. This is useful for forwarding to endpoints in the current application.
-
-
Post filters:
-
SendResponseFilter: Writes responses from proxied requests to the current response.
-
-
Error filters:
-
SendErrorFilter: Forwards to/error(by default) ifRequestContext.getThrowable()is not null. You can change the default forwarding path (/error) by setting theerror.pathproperty.
-
9.18.5. @EnableZuulProxy Filters
Creates a DiscoveryClientRouteLocator that loads route definitions from a DiscoveryClient (such as Eureka) as well as from properties. A route is created for each serviceId from the DiscoveryClient. As new services are added, the routes are refreshed.
In addition to the filters described earlier, the following filters are installed (as normal Spring Beans):
-
Pre filters:
-
PreDecorationFilter: Determines where and how to route, depending on the suppliedRouteLocator. It also sets various proxy-related headers for downstream requests.
-
-
Route filters:
-
RibbonRoutingFilter: Uses Ribbon, Hystrix, and pluggable HTTP clients to send requests. Service IDs are found in theRequestContextattribute,FilterConstants.SERVICE_ID_KEY. This filter can use different HTTP clients:-
Apache
HttpClient: The default client. -
Squareup
OkHttpClientv3: Enabled by having thecom.squareup.okhttp3:okhttplibrary on the classpath and settingribbon.okhttp.enabled=true. -
Netflix Ribbon HTTP client: Enabled by setting
ribbon.restclient.enabled=true. This client has limitations, including that it does not support the PATCH method, but it also has built-in retry.
-
-
SimpleHostRoutingFilter: Sends requests to predetermined URLs through an Apache HttpClient. URLs are found inRequestContext.getRouteHost().
-
9.18.6. Custom Zuul Filter Examples
Most of the following "How to Write" examples below are included Sample Zuul Filters project. There are also examples of manipulating the request or response body in that repository.
This section includes the following examples:
How to Write a Pre Filter
Pre filters set up data in the RequestContext for use in filters downstream.
The main use case is to set information required for route filters.
The following example shows a Zuul pre filter:
public class QueryParamPreFilter extends ZuulFilter {
@Override
public int filterOrder() {
return PRE_DECORATION_FILTER_ORDER - 1; // run before PreDecoration
}
@Override
public String filterType() {
return PRE_TYPE;
}
@Override
public boolean shouldFilter() {
RequestContext ctx = RequestContext.getCurrentContext();
return !ctx.containsKey(FORWARD_TO_KEY) // a filter has already forwarded
&& !ctx.containsKey(SERVICE_ID_KEY); // a filter has already determined serviceId
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
if (request.getParameter("sample") != null) {
// put the serviceId in `RequestContext`
ctx.put(SERVICE_ID_KEY, request.getParameter("foo"));
}
return null;
}
}The preceding filter populates SERVICE_ID_KEY from the sample request parameter.
In practice, you should not do that kind of direct mapping. Instead, the service ID should be looked up from the value of sample instead.
Now that SERVICE_ID_KEY is populated, PreDecorationFilter does not run and RibbonRoutingFilter runs.
If you want to route to a full URL, call ctx.setRouteHost(url) instead.
|
To modify the path to which routing filters forward, set the REQUEST_URI_KEY.
How to Write a Route Filter
Route filters run after pre filters and make requests to other services. Much of the work here is to translate request and response data to and from the model required by the client. The following example shows a Zuul route filter:
public class OkHttpRoutingFilter extends ZuulFilter {
@Autowired
private ProxyRequestHelper helper;
@Override
public String filterType() {
return ROUTE_TYPE;
}
@Override
public int filterOrder() {
return SIMPLE_HOST_ROUTING_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
return RequestContext.getCurrentContext().getRouteHost() != null
&& RequestContext.getCurrentContext().sendZuulResponse();
}
@Override
public Object run() {
OkHttpClient httpClient = new OkHttpClient.Builder()
// customize
.build();
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
String method = request.getMethod();
String uri = this.helper.buildZuulRequestURI(request);
Headers.Builder headers = new Headers.Builder();
Enumeration<String> headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String name = headerNames.nextElement();
Enumeration<String> values = request.getHeaders(name);
while (values.hasMoreElements()) {
String value = values.nextElement();
headers.add(name, value);
}
}
InputStream inputStream = request.getInputStream();
RequestBody requestBody = null;
if (inputStream != null && HttpMethod.permitsRequestBody(method)) {
MediaType mediaType = null;
if (headers.get("Content-Type") != null) {
mediaType = MediaType.parse(headers.get("Content-Type"));
}
requestBody = RequestBody.create(mediaType, StreamUtils.copyToByteArray(inputStream));
}
Request.Builder builder = new Request.Builder()
.headers(headers.build())
.url(uri)
.method(method, requestBody);
Response response = httpClient.newCall(builder.build()).execute();
LinkedMultiValueMap<String, String> responseHeaders = new LinkedMultiValueMap<>();
for (Map.Entry<String, List<String>> entry : response.headers().toMultimap().entrySet()) {
responseHeaders.put(entry.getKey(), entry.getValue());
}
this.helper.setResponse(response.code(), response.body().byteStream(),
responseHeaders);
context.setRouteHost(null); // prevent SimpleHostRoutingFilter from running
return null;
}
}The preceding filter translates Servlet request information into OkHttp3 request information, executes an HTTP request, and translates OkHttp3 response information to the Servlet response.
How to Write a Post Filter
Post filters typically manipulate the response. The following filter adds a random UUID as the X-Sample header:
public class AddResponseHeaderFilter extends ZuulFilter {
@Override
public String filterType() {
return POST_TYPE;
}
@Override
public int filterOrder() {
return SEND_RESPONSE_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext context = RequestContext.getCurrentContext();
HttpServletResponse servletResponse = context.getResponse();
servletResponse.addHeader("X-Sample", UUID.randomUUID().toString());
return null;
}
}| Other manipulations, such as transforming the response body, are much more complex and computationally intensive. |
9.18.7. How Zuul Errors Work
If an exception is thrown during any portion of the Zuul filter lifecycle, the error filters are executed.
The SendErrorFilter is only run if RequestContext.getThrowable() is not null.
It then sets specific javax.servlet.error.* attributes in the request and forwards the request to the Spring Boot error page.
9.18.8. Zuul Eager Application Context Loading
Zuul internally uses Ribbon for calling the remote URLs. By default, Ribbon clients are lazily loaded by Spring Cloud on first call. This behavior can be changed for Zuul by using the following configuration, which results eager loading of the child Ribbon related Application contexts at application startup time. The following example shows how to enable eager loading:
zuul:
ribbon:
eager-load:
enabled: true
10. Polyglot support with Sidecar
Do you have non-JVM languages with which you want to take advantage of Eureka, Ribbon, and Config Server? The Spring Cloud Netflix Sidecar was inspired by Netflix Prana. It includes an HTTP API to get all of the instances (by host and port) for a given service. You can also proxy service calls through an embedded Zuul proxy that gets its route entries from Eureka. The Spring Cloud Config Server can be accessed directly through host lookup or through the Zuul Proxy. The non-JVM application should implement a health check so the Sidecar can report to Eureka whether the app is up or down.
To include Sidecar in your project, use the dependency with a group ID of org.springframework.cloud
and artifact ID or spring-cloud-netflix-sidecar.
To enable the Sidecar, create a Spring Boot application with @EnableSidecar.
This annotation includes @EnableCircuitBreaker, @EnableDiscoveryClient, and @EnableZuulProxy.
Run the resulting application on the same host as the non-JVM application.
To configure the side car, add sidecar.port and sidecar.health-uri to application.yml.
The sidecar.port property is the port on which the non-JVM application listens.
This is so the Sidecar can properly register the application with Eureka.
The sidecar.secure-port-enabled options provides a way to enable secure port for traffic.
The sidecar.health-uri is a URI accessible on the non-JVM application that mimics a Spring Boot health indicator.
It should return a JSON document that resembles the following:
{
"status":"UP"
}The following application.yml example shows sample configuration for a Sidecar application:
server:
port: 5678
spring:
application:
name: sidecar
sidecar:
port: 8000
health-uri: http://localhost:8000/health.jsonThe API for the DiscoveryClient.getInstances() method is /hosts/{serviceId}.
The following example response for /hosts/customers returns two instances on different hosts:
[
{
"host": "myhost",
"port": 9000,
"uri": "https://myhost:9000",
"serviceId": "CUSTOMERS",
"secure": false
},
{
"host": "myhost2",
"port": 9000,
"uri": "https://myhost2:9000",
"serviceId": "CUSTOMERS",
"secure": false
}
]This API is accessible to the non-JVM application (if the sidecar is on port 5678) at localhost:5678/hosts/{serviceId}.
The Zuul proxy automatically adds routes for each service known in Eureka to /<serviceId>, so the customers service is available at /customers.
The non-JVM application can access the customer service at localhost:5678/customers (assuming the sidecar is listening on port 5678).
If the Config Server is registered with Eureka, the non-JVM application can access it through the Zuul proxy.
If the serviceId of the ConfigServer is configserver and the Sidecar is on port 5678, then it can be accessed at localhost:5678/configserver.
Non-JVM applications can take advantage of the Config Server’s ability to return YAML documents. For example, a call to sidecar.local.spring.io:5678/configserver/default-master.yml might result in a YAML document resembling the following:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
password: password
info:
description: Spring Cloud Samples
url: https://github.com/spring-cloud-samplesTo enable the health check request to accept all certificates when using HTTPs set sidecar.accept-all-ssl-certificates to `true.
11. Retrying Failed Requests
Spring Cloud Netflix offers a variety of ways to make HTTP requests.
You can use a load balanced RestTemplate, Ribbon, or Feign.
No matter how you choose to create your HTTP requests, there is always a chance that a request may fail.
When a request fails, you may want to have the request be retried automatically.
To do so when using Sping Cloud Netflix, you need to include Spring Retry on your application’s classpath.
When Spring Retry is present, load-balanced RestTemplates, Feign, and Zuul automatically retry any failed requests (assuming your configuration allows doing so).
11.1. BackOff Policies
By default, no backoff policy is used when retrying requests.
If you would like to configure a backoff policy, you need to create a bean of type LoadBalancedRetryFactory and override the createBackOffPolicy method for a given service, as shown in the following example:
@Configuration
public class MyConfiguration {
@Bean
LoadBalancedRetryFactory retryFactory() {
return new LoadBalancedRetryFactory() {
@Override
public BackOffPolicy createBackOffPolicy(String service) {
return new ExponentialBackOffPolicy();
}
};
}
}11.2. Configuration
When you use Ribbon with Spring Retry, you can control the retry functionality by configuring certain Ribbon properties.
To do so, set the client.ribbon.MaxAutoRetries, client.ribbon.MaxAutoRetriesNextServer, and client.ribbon.OkToRetryOnAllOperations properties.
See the Ribbon documentation for a description of what these properties do.
Enabling client.ribbon.OkToRetryOnAllOperations includes retrying POST requests, which can have an impact
on the server’s resources, due to the buffering of the request body.
|
| The property names are case-sensitive, and since some of these properties are defined in the Netflix Ribbon project, they are in Pascal Case and the ones from Spring Cloud are in Camel Case. |
In addition, you may want to retry requests when certain status codes are returned in the response.
You can list the response codes you would like the Ribbon client to retry by setting the clientName.ribbon.retryableStatusCodes property, as shown in the following example:
clientName:
ribbon:
retryableStatusCodes: 404,502You can also create a bean of type LoadBalancedRetryPolicy and implement the retryableStatusCode method to retry a request given the status code.
11.2.1. Zuul
You can turn off Zuul’s retry functionality by setting zuul.retryable to false.
You can also disable retry functionality on a route-by-route basis by setting zuul.routes.routename.retryable to false.
12. HTTP Clients
Spring Cloud Netflix automatically creates the HTTP client used by Ribbon, Feign, and Zuul for you.
However, you can also provide your own HTTP clients customized as you need them to be.
To do so, you can create a bean of type CloseableHttpClient if you
are using the Apache HTTP Client or OkHttpClient if you are using OK HTTP.
| When you create your own HTTP client, you are also responsible for implementing the correct connection management strategies for these clients. Doing so improperly can result in resource management issues. |
13. Modules In Maintenance Mode
Placing a module in maintenance mode means that the Spring Cloud team will no longer be adding new features to the module. We will fix blocker bugs and security issues, and we will also consider and review small pull requests from the community.
We intend to continue to support these modules for a period of at least a year from the general availability of the Greenwich release train.
The following Spring Cloud Netflix modules and corresponding starters will be placed into maintenance mode:
-
spring-cloud-netflix-archaius
-
spring-cloud-netflix-hystrix-contract
-
spring-cloud-netflix-hystrix-dashboard
-
spring-cloud-netflix-hystrix-stream
-
spring-cloud-netflix-hystrix
-
spring-cloud-netflix-ribbon
-
spring-cloud-netflix-turbine-stream
-
spring-cloud-netflix-turbine
-
spring-cloud-netflix-zuul
| This does not include the Eureka or concurrency-limits modules. |
14. Configuration properties
To see the list of all Spring Cloud Netflix related configuration properties please check the Appendix page.