In the following section we will describe in more depth the rationale behind the presented opinionated pipeline. We will go through each deployment step and describe it in details.
. ├── common ├── concourse ├── docs └── jenkins
In the common folder you can find all the Bash scripts containing the pipeline logic. These
scripts are reused by both Concourse and Jenkins pipelines.
In the concourse folder you can find all the necessary scripts and setup to run Concourse demo.
In the docs section you have the whole documentation of the project.
In the jenkins folder you can find all the necessary scripts and setup to run Jenkins demo.
This repository can be treated as a template for your pipeline. We provide some opinionated implementation that you can alter to suit your needs. The best approach to use it to build your production projects would be to download the Spring Cloud Pipelines repository as ZIP, then init a Git project there and modify it as you wish.
$ # pass the branch (e.g. master) or a particular tag (e.g. v1.0.0.RELEASE) $ SC_PIPELINES_RELEASE=... $ curl -LOk https://github.com/spring-cloud/spring-cloud-pipelines/archive/${SC_PIPELINES_RELEASE}.zip $ unzip ${SC_PIPELINES_RELEASE}.zip $ cd spring-cloud-pipelines-${SC_PIPELINES_RELEASE} $ git init $ # modify the pipelines to suit your needs $ git add . $ git commit -m "Initial commit" $ git remote add origin ${YOUR_REPOSITORY_URL} $ git push origin master
![[Note]](images/note.png) | Note |
|---|---|
Why aren’t you simply cloning the repo? This is meant to be a seed for building new, versioned pipelines for you. You don’t want to have all of our history dragged along with you, don’t you? |
You can use Spring Cloud Pipelines to generate pipelines for all projects in your system. You can scan all your repositories (e.g. call the Stash / Github API and retrieve the list of repos) and then…
- For Jenkins, call the seed job and pass the
REPOSparameter that would contain the list of repositories - For Concourse, you’d have to call
flyand set pipeline for every single repo
You can use Spring Cloud Pipelines in such a way that each project contains its own pipeline definition in its code. Spring Cloud Pipelines clones the code with the pipeline definitions (the bash scripts) so the only piece of logic that could be there in your application’s repository would be how the pipeline should look like.
- For Jenkins, you’d have to either set up the
Jenkinsfileor the jobs using Jenkins Job DSL plugin in your repo. Then in Jenkins whenever you set up a new pipeline for a repo then you reference the pipeline definition in that repo. - For Concourse, each project contains its own pipeline steps and it’s up to the project to set up the pipeline.
Let’s take a look at the flow of the opinionated pipeline

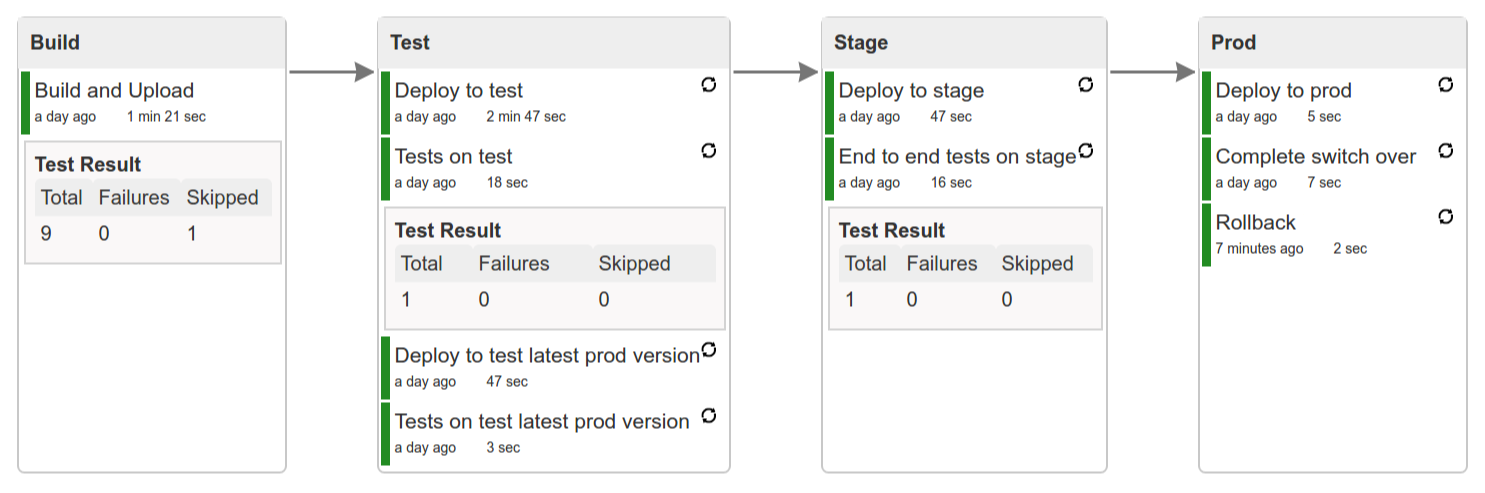
We’ll first describe the overall concept behind the flow and then we’ll split it into pieces and describe every piece independently.
So we’re on the same page let’s define some common vocabulary. We discern 4 typical environments in terms of running the pipeline.
- build environment is a machine where the building of the application takes place. It’s a CI / CD tool worker.
- test is an environment where you can deploy an application to test it. It doesn’t resemble production, we can’t be sure of it’s state (which application is deployed there and in which version). It can be used by multiple teams at the same time.
- stage is an environment that does resemble production. Most likely applications are deployed there in versions that correspond to those deployed to production. Typically databases there are filled up with (obfuscated) production data. Most often this environment is a single, shared one between many teams. In other words in order to run some performance, user acceptance tests you have to block and wait until the environment is free.
- prod is a production environment where we want our tested applications to be deployed for our customers.
Unit tests - tests that are executed on the application during the build phase. No integrations with databases / HTTP server stubs etc. take place. Generally speaking your application should have plenty of these to have fast feedback if your features are working fine.
Integration tests - tests that are executed on the built application during the build phase. Integrations with in memory databases / HTTP server stubs take place. According to the test pyramid, in most cases you should have not too many of these kind of tests.
Smoke tests - tests that are executed on a deployed application. The concept of these tests is to check the crucial parts of your application are working properly. If you have 100 features in your application but you gain most money from e.g. 5 features then you could write smoke tests for those 5 features. As you can see we’re talking about smoke tests of an application, not of the whole system. In our understanding inside the opinionated pipeline, these tests are executed against an application that is surrounded with stubs.
End to end tests - tests that are executed on a system composing of multiple applications. The idea of these tests is to check if the tested feature works when the whole system is set up. Due to the fact that it takes a lot of time, effort, resources to maintain such an environment and that often those tests are unreliable (due to many different moving pieces like network database etc.) you should have a handful of those tests. Only for critical parts of your business. Since only production is the key verifier of whether your feature works, some companies don’t even want to do those and move directly to deployment to production. When your system contains KPI monitoring and alerting you can quickly react when your deployed application is not behaving properly.
Performance testing - tests executed on an application or set of applications to check if your system can handle big load of input. In case of our opinionated pipeline these tests could be executed either on test (against stubbed environment) or stage (against the whole system)
Before we go into details of the flow let’s take a look at the following example.
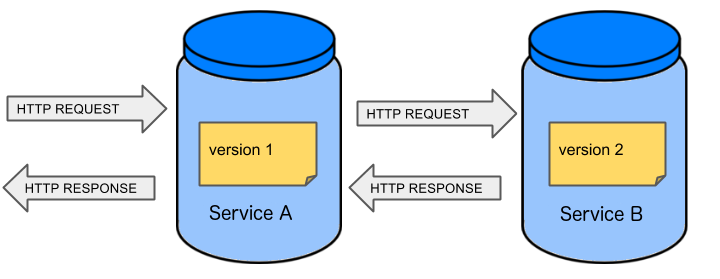
When having only a handful of applications, performing end to end testing is beneficial. From the operations perspective it’s maintainable for a finite number of deployed instances. From the developers perspective it’s nice to verify the whole flow in the system for a feature.
In case of microservices the scale starts to be a problem:
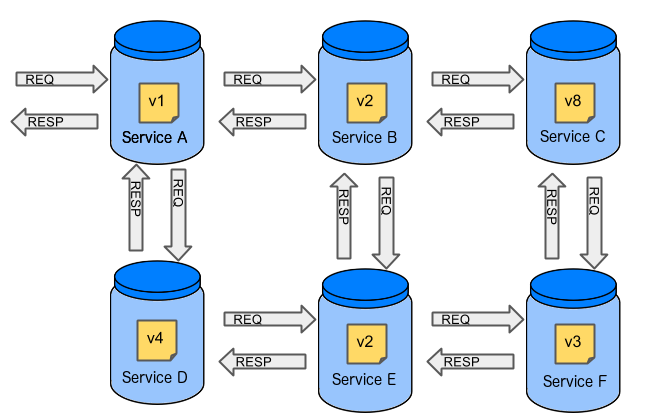
The questions arise:
Should I queue deployments of microservices on one testing environment or should I have an environment per microservice?
- If I queue deployments people will have to wait for hours to have their tests ran - that can be a problem
To remove that issue I can have an environment per microservice
- Who will pay the bills (imagine 100 microservices - each having each own environment).
- Who will support each of those environments?
- Should we spawn a new environment each time we execute a new pipeline and then wrap it up or should we have them up and running for the whole day?
In which versions should I deploy the dependent microservices - development or production versions?
- If I have development versions then I can test my application against a feature that is not yet on production. That can lead to exceptions on production
- If I test against production versions then I’ll never be able to test against a feature under development anytime before deployment to production.
One of the possibilities of tackling these problems is to… not do end to end tests.
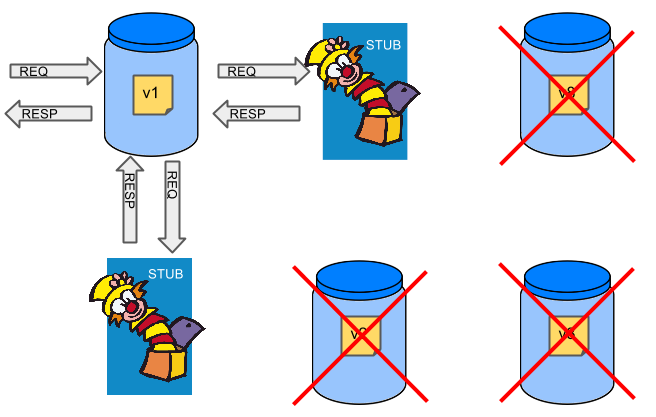
If we stub out all the dependencies of our application then most of the problems presented above disappear. There is no need to start and setup infrastructure required by the dependant microservices. That way the testing setup looks like this:
Such an approach to testing and deployment gives the following benefits (thanks to the usage of Spring Cloud Contract):
- No need to deploy dependant services
- The stubs used for the tests ran on a deployed microservice are the same as those used during integration tests
- Those stubs have been tested against the application that produces them (check Spring Cloud Contract for more information)
- We don’t have many slow tests running on a deployed application - thus the pipeline gets executed much faster
- We don’t have to queue deployments - we’re testing in isolation thus pipelines don’t interfere with each other
- We don’t have to spawn virtual machines each time for deployment purposes
It brings however the following challenges:
- No end to end tests before production - you don’t have the full certainty that a feature is working
- First time the applications will talk in a real way will be on production
Like every solution it has its benefits and drawbacks. The opinionated pipeline allows you to configure whether you want to follow this flow or not.
The general view behind this deployment pipeline is to:
- test the application in isolation
- test the backwards compatibility of the application in order to roll it back if necessary
- allow testing of the packaged app in a deployed environment
- allow user acceptance tests / performance tests in a deployed environment
- allow deployment to production
Obviously the pipeline could have been split to more steps but it seems that all of the aforementioned actions comprise nicely in our opinionated proposal.
Spring Cloud Pipelines uses Bash scripts extensively. Below you can find the list of software that needs to be installed on a CI server worker for the build to pass.
![[Tip]](images/tip.png) | Tip |
|---|---|
In the demo setup all of these libraries are already installed. |
apt-get -y install \
bash \
git \
tar \
zip \
curl \
ruby \
wget \
unzip \
python \
jq![[Important]](images/important.png) | Important |
|---|---|
In the Jenkins case you will also need |
Each application can contain a file called sc-pipelines.yml with the following structure:
lowercaseEnvironmentName1: services: - type: service1Type name: service1Name coordinates: value - type: service2Type name: service2Name key: value lowercaseEnvironmentName2: services: - type: service3Type name: service3Name coordinates: value - type: service4Type name: service4Name key: value
For a given environment we declare a list of infrastructure services that we want to have deployed. Services have
type(example:eureka,mysql,rabbitmq,stubrunner) - this value gets then applied to thedeployServiceBash function- [KUBERNETES] for
mysqlyou can pass the database name via thedatabaseproperty name- name of the service to get deployedcoordinates- coordinate that allows you to fetch the binary of the service. Examples: It can be a maven coordinategroupid:artifactid:version, docker imageorganization/nameOfImage, etc.- arbitrary key value pairs - you can customize the services as you wish
The stubrunner type can also have the useClasspath flag turned on to true
or false.
Example:
test: services: - type: rabbitmq name: rabbitmq-github-webhook - type: mysql name: mysql-github-webhook - type: eureka name: eureka-github-webhook coordinates: com.example.eureka:github-eureka:0.0.1.M1 - type: stubrunner name: stubrunner-github-webhook coordinates: com.example.eureka:github-analytics-stub-runner-boot-classpath-stubs:0.0.1.M1 useClasspath: true stage: services: - type: rabbitmq name: rabbitmq-github - type: mysql name: mysql-github - type: eureka name: github-eureka coordinates: com.example.eureka:github-eureka:0.0.1.M1
When the deployment to test or deployment to stage occurs, Spring Cloud Pipelines will:
- for
testenvironment, delete existing services and redeploy the ones from the list - for
stageenvironment, if the service is not available it will get deployed. Otherwise nothing will happen